rabbitmq_zeromq_kafka是一个层级的东西吗__相互之间有哪些优缺点
属于分布式消息队列相关的问题。
关注者
1,815
被浏览
293,016
KDF5000 也关注了该问题
关注问题写回答
邀请回答
好问题 71
添加评论
分享
查看全部 26 个回答 (opens new window)

飞书-喜欢刨根问底的攻城师
等 249 人赞同了该回答
先说ZeroMQ。这东西叫【Zero】MQ,其实压根就不是我们传统意义上的MQ。它是一个用于网络编程的SDK,目标是给常见的网络通讯方式提供一个更好用的接口,在没有“broker”的情况下实现网络通讯。
ZeroMQ (also spelled ØMQ, 0MQ or ZMQ) is a high-performance asynchronous messaging library, aimed at use in distributed or concurrent applications. It provides a message queue, but unlike message-oriented middleware, a ZeroMQ system can run without a dedicated message broker.
……
The philosophy of ZeroMQ starts with the zero. The zero is for zero broker (ZeroMQ is brokerless), zero latency, zero cost (it’s free), and zero administration.
比如,想实现一个1个req/resp的机制。用常规的socket是个相当麻烦的事。从客户端 (opens new window)要connect,按照报格式序列化 (opens new window)数据,发数据,接收数据,关闭连接;而服务端要listen,accept,读取数据,发送数据……这还不算每个步骤的错误处理,缓冲区的管理,多路复用 (opens new window)……。(所以普通人估计直接就上http了)。再比如fanout,fanin,master-worker……这些模式也都相当麻烦。而ZeroMQ提供了SDK可以帮助开发者快速实现这些功能。
不过ZeroMQ提供的某些模式已经带有了很明显的的broker的特征。不知道作者是如何考虑的。
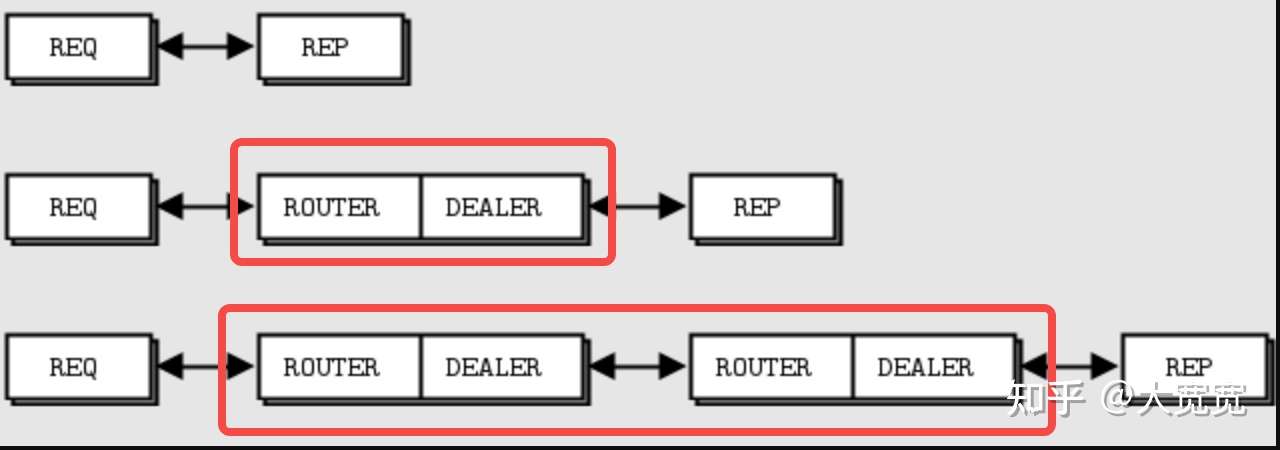
高级Req/Resp模式
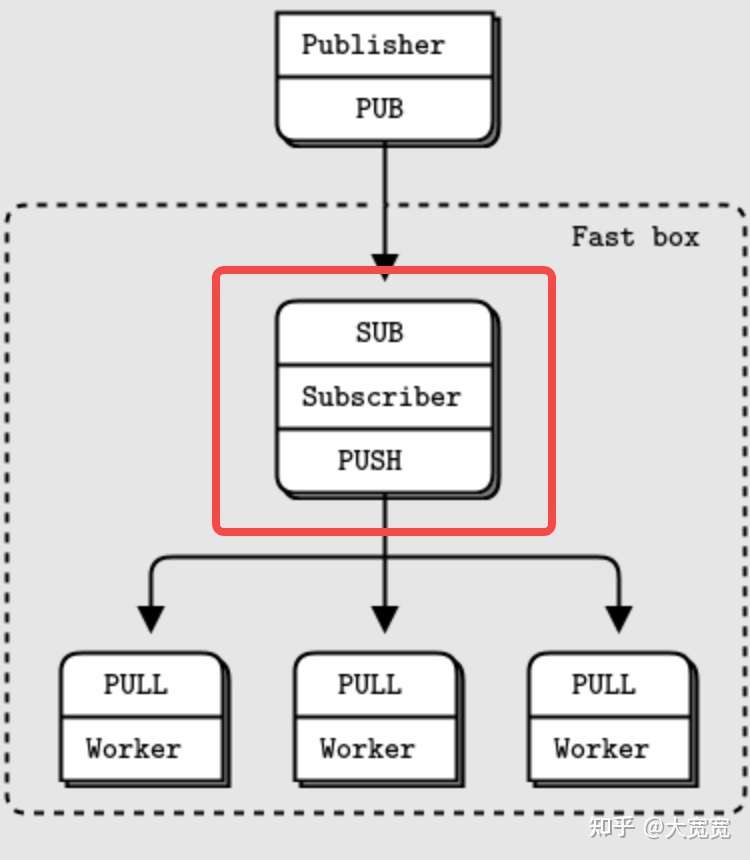
高级pub/sub模式
但个人认为ZeroMQ适合用来搭建一个框架,而并非被直接被业务使用。比如,ZeroMQ完全不解决消息高可用的的问题。消息落盘这种事并不在ZeroMQ的scope里。因为它和常规MQ的差异过于巨大(除了名字里带mq,和mq没有半毛钱关系),后边就不再讨论了。从应用角度,除非是做网络编程的,我也不太建议进一步深入了解它。
RabbitMQ代表了传统的broker为中心的MQ,其设计和信箱很像。被发送的消息经过1个或者多个broker的处理,最终进入一个消费者的信箱(queue)。消费者正确处理后,这个message就被删除了。如果存在多个不同的,彼此独立的consumer,可以设置各自独立的queue,各不影响。这里说”以broker为中心“就是着重强调”转发能力”。一个broker可以根据路由规则进行投递,可以fanout,可以根据tag做部分message的过滤。多个broker之间还可以“接力”。message还能有TTL生命周期。在复杂的企业级信息系统里实现message通讯和协作。RabbitMQ也满足多个标准,如AMQP,MQTT,STOMP等。遵守这些协议可以帮助上游在多个MQ上做迁移。
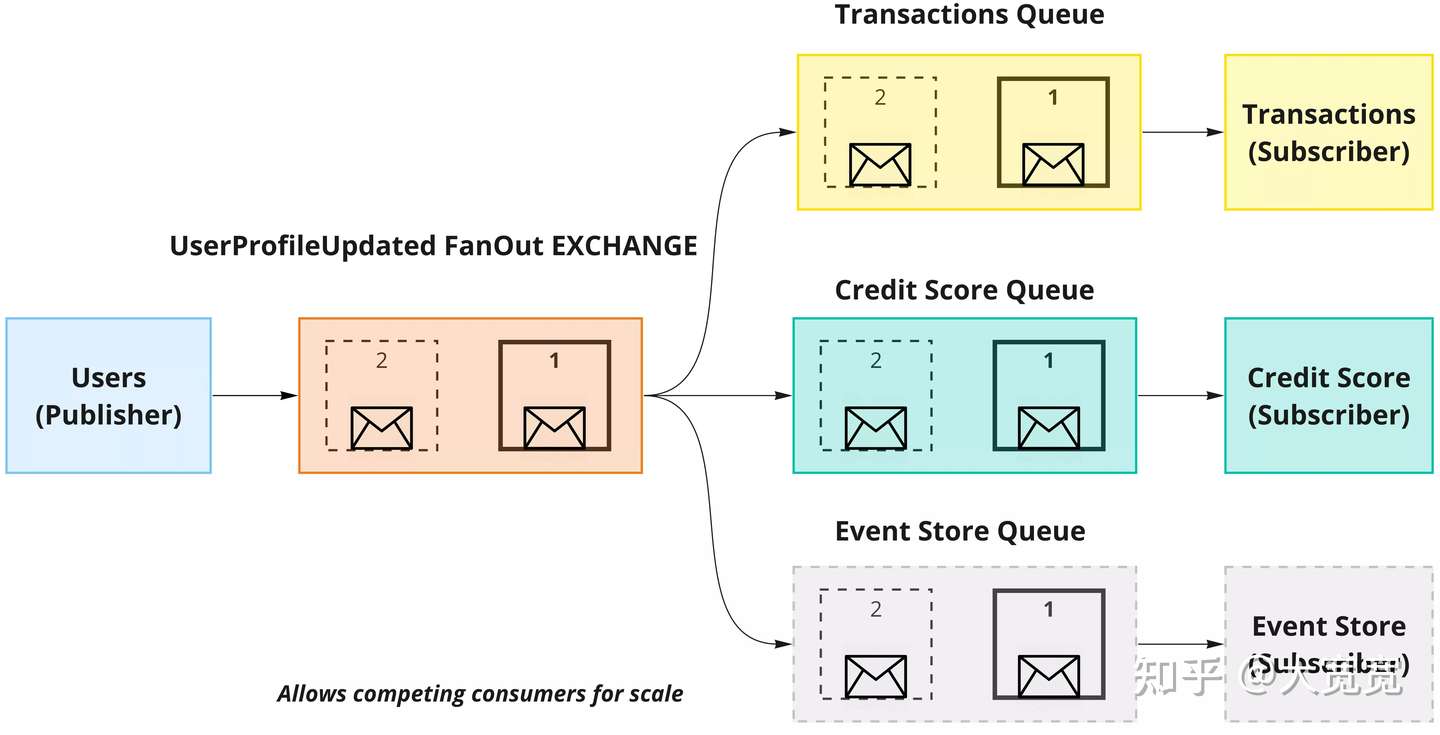
这类MQ从使用者角度,用起来非常方便。producer只管发,consumer只管收。业务逻辑都是broker上面配置。
但这种设计也带来一些根本性的问题,让他非常不适合在一些场景中使用。
- 首先是保序性。RabbitMQ(或者这类MQ)都只能保证在单broker+单consumer+不自动进入死信队列的情况下实现保证严格的顺序。但是单broker+单consumer是不可扩展的,无法实现更高的吞吐。类似于数据库Syncer之类需要严格顺序的服务就无法实现了。
- 因为存在多个queue,因此一个message可能被写入多次,存在写放大的问题。但既然支持了多个queue,就不可能不复制message。那么吞吐就会受到极大的影响。类似于日志流式处理的场景就无法支持了。
- 一个message被消费了,就会被清理。那么如果一个流处理存在bug,产生了错误的结果,就意味着无论如何都无法重新修正了。除非数据源可以把messge重新发一遍。如果MQ拓扑很复杂,这几乎就不可能。类似的,也没法做到“半夜把白天的数据用批处理重新跑一遍”之类的事情。
所以Kafka从一开始就实现了一个和传统的MQ完全不同的”MQ“。(我感觉叫他logbase可能更合适)它的出现一开始就是面向大数据,高吞吐的场景。尽管Kafka里也有个“broker”。但这个broker干的事情和RabbitMQ的“根据业务逻辑转发和处理”完全不同。Kafka的broker仅仅是**以理论上最快的速度来将消息写入,供consuemr读取。**在磁盘上,最快的写入就是顺序写(当时HDD还大量存在,HDD的顺序写和随机写的性能差异比SSD大得多)。因此Kafka的broker就是将数据的以“Append only”的形式写入文件。(对比传统MQ一般会用某种数据库)。这个Append only file模型上实际就是个log(留意这里的log的意思并不是业务日志,是指总是追加写的数据模型)。
当然,Kafka为了提高吞吐,还采用了很多其他的办法,比如双buffer,IO多路复用,零拷贝等。但Append Only File是Kafka(以及kafka这一类MQ,如RocketMQ)在数据模型上最显著的不同。
而consumer不会各自维护独立的“queue”,而是都直接读取同一份log文件。只不过不同consumer各自维护不同的读取位置。在早期的版本中这些位置被存在zk里,后来改到了虚拟的topic。而message的删除和谁消费完全没有关系,是需要独立配置的,比如可以配置为7天过期。只要存储够大,可以保证message一直不丢失,可以反复消费(只要调整读取位置就行了)。
并且,对于同一个log,message一旦写入,位置就不会变了。因此同样一个文件的任意consumer都可以保证顺序。这个文件在概念上被称为一个topic的partition。简单说就是Kafka的partition+consumer可以保证顺序。而Kafka可以保证对于各一个partition最多只能有一个consumer线程消费。因此对于这个consumer可以完全不担心顺序(但可以启动多个consumer消费同一个partition,除了活跃的那个consumer,其余的可以当做热备)。
这样,kafka就实现了一个可以极大吞吐的,有顺序保证的,可以被反复消费log文件队列。而log这种数据模型,其实是很多数据系统的内部核心数据结构。比如在mysql中有binlog负责主从同步,redo log负责数据恢复;在raft中每个节点都会维护一个log做total order broadcast等等。

传统MQ只负责转发和被消费前临时存储,而Kafka本身就是数据,因此Kafka像数据库那样认真的考虑了数据高可用的问题,实现了多副本,自动切主等功能。
在2010~2015年,因为大数据流式处理的兴起,Kafka成为数据分析领域无可替代的中间件(后来才有了RocketMQ和pulsar)。而对于大多数线上处理,只需要消息1跳的场景,不需要灵活配置转发规则的场景,Kafka也可以用。且吞吐高,相对的省资源,还可以省一套运维,顶多就是费点磁盘(便宜得很)。因此很多公司会选择运维几套不同的Kafka集群同时支持线上和离线业务。
所以你会发现,
- 收集线上log可以用kafka
- ETL可以用kafka。
- 多数据中心数据同步可以用kafka。
- 线上发个报警做推送通道可以用kafka。
- 做数据库降级处理的请求暂存可以用kafka。
- 线上业务削峰填谷抗流量还可以用kafka。
- 实现CQRS也可以用Kafka。
- ……
kafka如万金油一般的存在。kafka用起来就像是一个”log库“,基于它可以搭建各种各样的设施。相比之下,传统MQ你不会太关心他的存在和配置,仅仅是写消息和读消息而已。
所以我不是很喜欢那种“横评“——RabbitMQ支持什么什么,Kafka支持什么什么。这种横评传达的意味是二者可以直接对比。但实际上他们用起来感觉完全不一样。
Kafka本身极大的降低了broker模型的复杂度,因此不支持各种骚功能:
- 想要多集群间转发?kafka broker不支持,一开始需要自己写代码consume+process+produce。后来kafka基于这个模式提供了stream api,还支持“事务”(exactly once processing)
- 想要延迟消息?kafka不支持,需要自己写个业务服务定时去pull。为了大流量转发需求,可以考虑自己实现一个时间轮的服务。
- 想要死信队列?没有built-in,但你可以自己弄个topic当死信队列。(但使用私信队列也就意味着必定无序)
同时为了性能,不可避免的发送和消费需要耦合一点点业务。比如多个partition的分发,只有业务逻辑上才能知道哪些消息是有序的。因此业务上自己要定义partition key。为了性能业务一般也要自己对消息做序列化(json,avro,pb等)。运维为了一致性要多搞一套zk(新版kafka已经在逐渐去zk化,但做法是自己实现一套分布式consensus协议)。
次时代的MQ会考虑在保留Kafka的优点的基础之上,再引入一些传统MQ的能力(比如延迟队列),以及一些全新的能力(比如租户隔离,事务消息,审计,资源池……)。找机会再细讲。