greenplum_a_hybrid_database_for_transactional_and_analytical_workloads
# Greenplum: A Hybrid Database for Transactional and Analytical Workloads
*INTRODUCTION*
greenplum 是基于 Postgres 的 shared-nothing MPP 开源数据库,扩展了 postgres 的分布式处理能力。本文主要讲在 Greenplum6 这个版本上 GP 做的融合 AP 和 TP 两种场景的设计思路以及优化方法,主要包括 GP 的 MPP 架构的介绍,LOCK OPTIMIZATION 锁优化,DISTRIBUTED TRANSACTION MANAGEMENT 分布式事务管理,RESOURCE ISOLATION 资源隔离几部分的内容,通过以上的优化显著提升了 Gre enplum6 对于混合负载的处理能力。
下文中以 GP 作为 Greenplum 的缩写
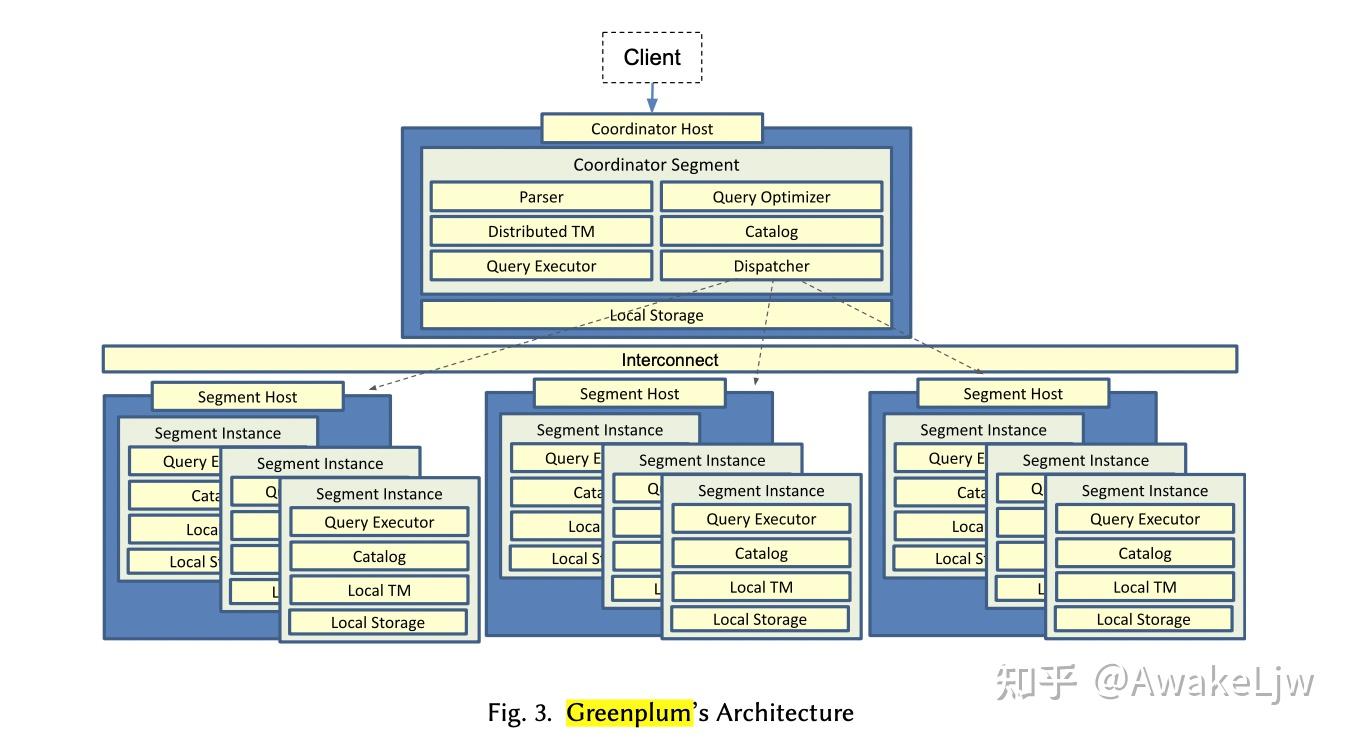
# *1. GREENPLUM‘S MPP ARCHITECTURE*
Greenplum 作为经典的 OLAP 数据库支持 PB 级数据的存储和分析能力,主要在淡季数据库上扩展了以下能力:Data Scalability,Compute Scalability, High Availability。Greenplum 是 shared-nothing 的 cluster 架构 , 主要组成部分包括 Coordinator 和 Segments,Coordinator 只有一个,用来连接 client,并且接收请求,通过 Query Optimizer 生成分布式计划,Dispatcher 分发分布式计划,收集结果返回给客户端,Segments 节点既是数据的存储节点也是计算节点,segment 之间的非共享的,这也是 shared-nothing 的来源。在众多的 segments 中,有部分是作为 mirrors,他们不参与计算,只是接收 WAL 日志动态回放来保证高可用(High Availability)。
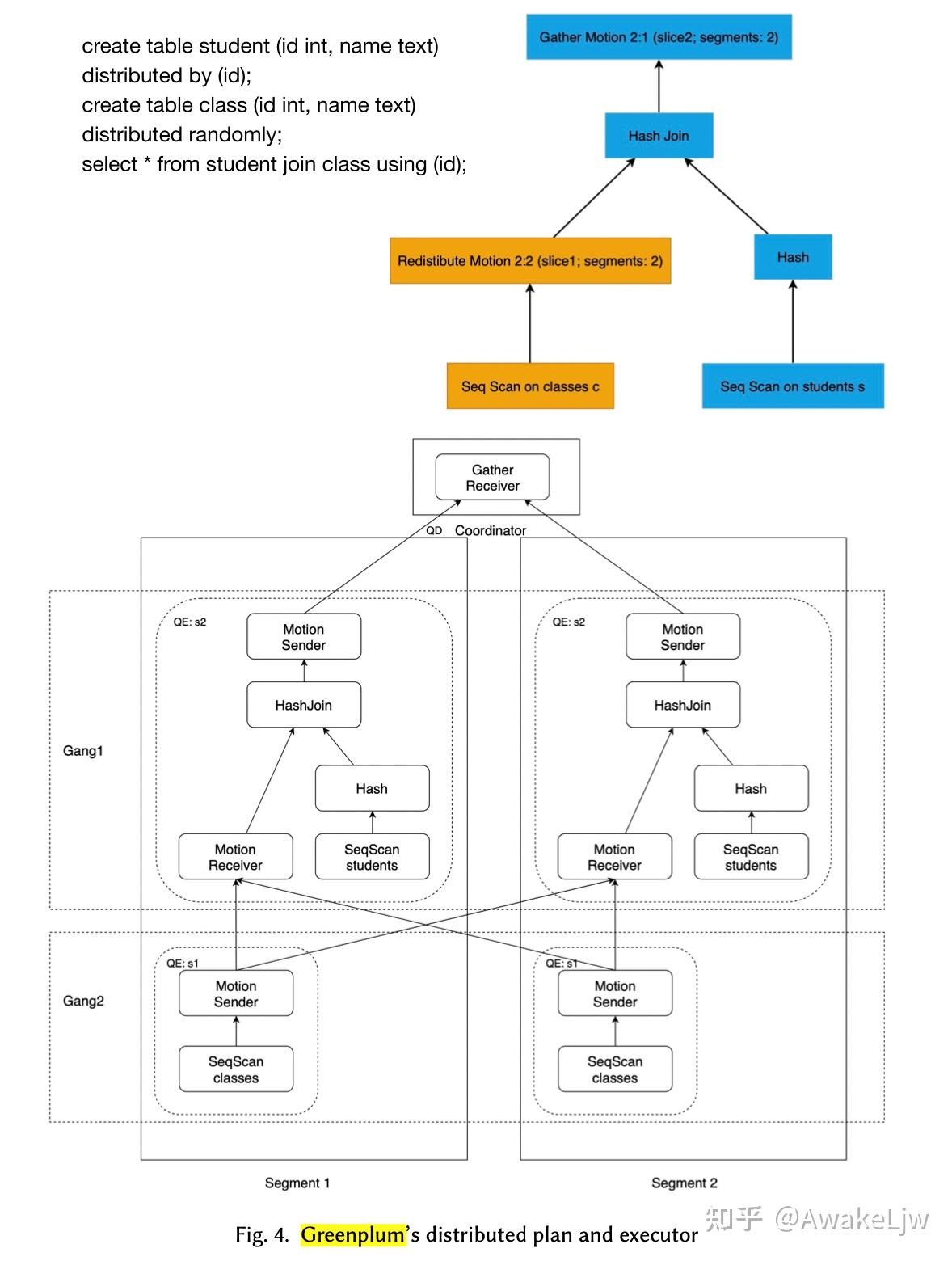
*1.1 Distributed Plan and Distributed Executor*
GP 的计算弹性是通过分布式执行实现的。在传统的 pull 型执行框架中,分布式计划增加了一个很重要的算子 Motion 算子(又可以叫做 exchange 算子),主要用来作为数据的重分布的。在 GP 中 Motion 算子将计划切割成 pieces,每个 piece 在 GP 中被叫做 slice,slice 可以在不同的 process,不同的 segment 中执行。执行 slice 的分布式的 processes 组成一个 gang。
以下图中的 query 为例,一个完成的执行计划被划分为 3 个 slice,Gather 代表的 slice 在 coordinator 节点上执行,用来汇总数据返回执行结果。Gather 一下的执行计划分为两个 slice,分别在两个 segment 上执行,一个 slice 执行 seqscan,并把数据发送到 motion 的缓冲区,另一个 slice 从缓冲区读取数据并执行 join 算子,将结果发送到 Coordinator 节点。motion 算子在这里执行的是 redistribute 的操作。
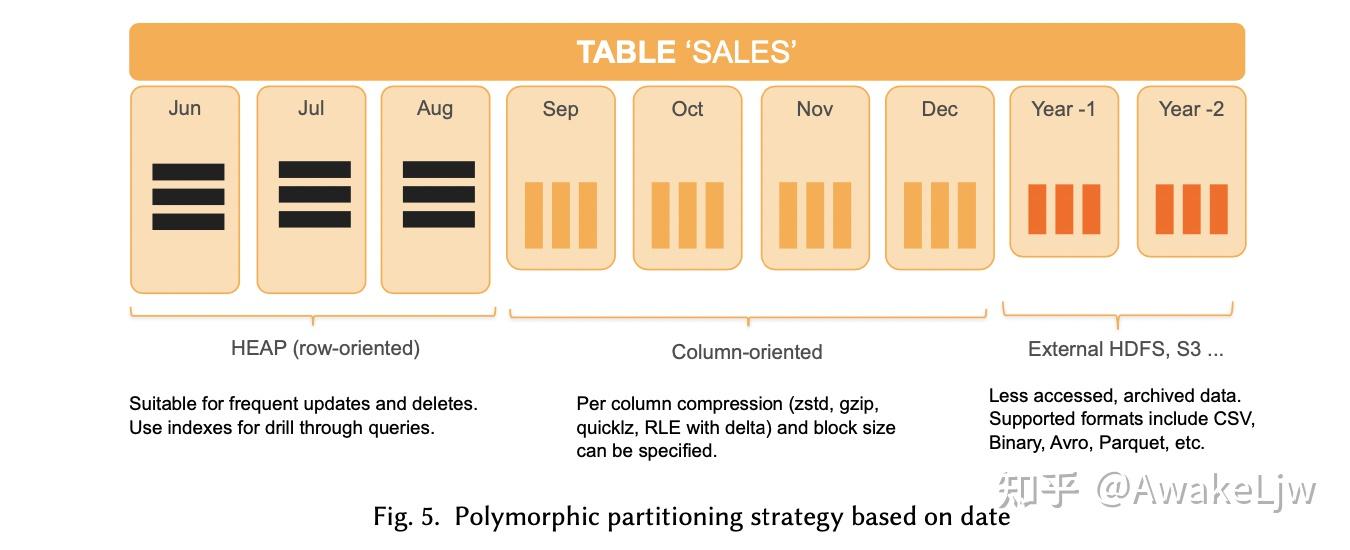
*1.2 Hybrid Storage and Optimizer*
GP 除了支持 PG 原生的 heap 表(面向行存储,有固定大小的 block 和进程共享的 buffer)外,扩展了两种新的表类型,AO-row(append only 的行存表)和 AO-column(append only 的列存表),在 AO-column 中每个列分配一个文件,并且可以使用 RLE 算法压缩。所有的 AO tables 都可以使用 zstd,quicklz 和 zlib 压缩存储。
在 GP 中一个表可以按照 list 或者 range 分区,根据分区键划分分区的同一层次下可以是 heap,ao-column 和 ao-row,另外也可以把一些历史数据存储在 S3 或者 HDFS 上,类似于冷热数据的存储模式。
GP 提供了两种优化器可供选择,一种是 Orca 优化器是为分析性负载设计的 CBO 优化器,一种是 MPP-aware 的 PostgreSQL 的优化器,可处理事务型负载。用户可以在使用时指定会话级别或者数据库级别的优化器来处理不同的工作负载。
# *2. LOCK OPTIMIZATION*
Greenplum 中锁的类型基本和 pg 的一致,一共有 8 级别,如果两把锁的 level 相加大于等于 8,那这两把锁就是互斥的,不能并行执行。在 PG 中锁存储在共享内存中,所以当死锁发生时,可以在共享内存中扫描锁信息并 break 它来解决死锁的问题。GP 在这一基础上解决了全局死锁的问题,这个因为,不同的 DML 可能在不同的 segment 上执行,每个 segment 只能获取 local 的锁信息,所以需要一个全局的死锁检测器来检测并打破死锁,在 GP 中叫做 GDD(Global Deadlock Detection)。
GDD 使用的是贪心算法,通过收集每个 segment 上的 local wait-for graph,构建全局的 wait-for graph。在算法中有几个基本的概念需要说明
- vertex 表示的是事务
- edge 表示的是从等待锁的事务到持有锁的事务的有向边。
- vertex 的 in-coming edges 和 outgong edges 的个数代表的是顶点的入度和出度
$$ deg^{(G)}(V) 代表顶点 V 的全局出度。de g_{i}(V) 代表的是 segment i 中的本地出度 $$ 因为每个 segment 的 wait-for graph 是异步收集的,所以无法避免因为一些网络延迟导致锁信息不准确,所以 GDD 使用贪心的算法,核心是移除可能会继续执行的等待边。所有没有可以移除的边时,仍然有剩余的 waiting edges,则证明发生了死锁。实际执行时会周期性启动一个 GDD 守护进程去执行检查 edges 是否合法,是否有死锁发生。
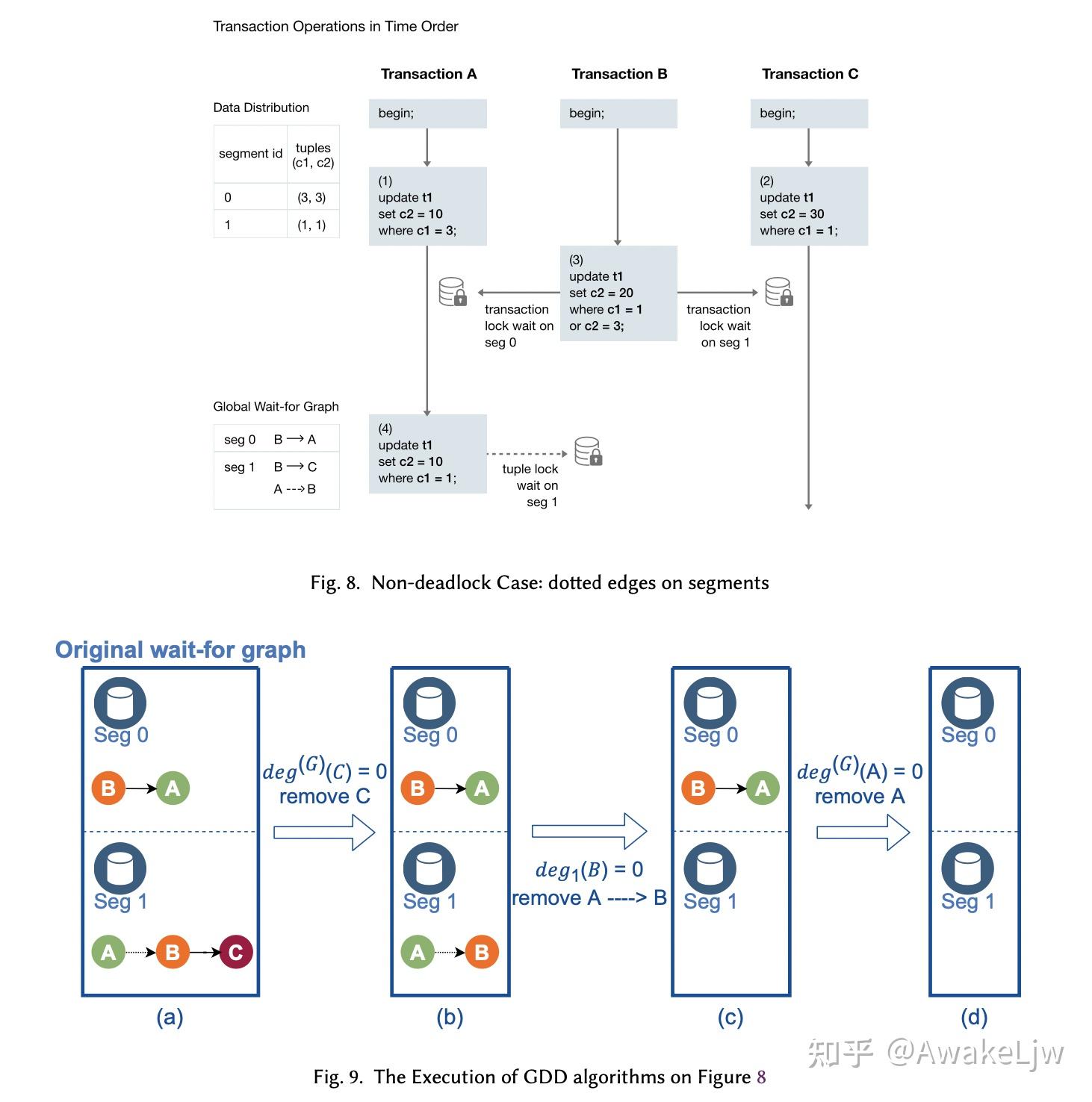
- Solid edges:表示必须等待持有锁的事务结束后才能消失的 edges,典型的就是 update 或者 insert 中持有的表锁。
- dotted edges:表示持有锁的事务没有结束也可以释放锁,比如在 update 一行数据前持有的行锁,这种锁可以在事务执行过程中释放锁。
GDD 算法主要分为两部分,第一步是遍历所有的顶点,如果全局出度为 0,就删除对应的顶点,第二步是遍历 local graph,寻找本地出度为 0 的顶点并删除,直到没有可以删除的顶点后停止。如果让然有遗留的 edges,则表示发生了死锁。

举例来说:有三个事务 A,B,C, 构建的 global wait-for graph 如图所示,首先,C 的全局出度为 0,所以 C 可以删除,其次在 segment1 中 A 到 B 的 tuple lock 是一个 dotted edges,也就是事务 B 在 segment1 上没有被阻塞,所以事务 B 可以释放 c1=1 上的锁,这时(4)就可以抢到锁。最后在 segment0 上当事务 A 执行成功后 B 就可以拿到锁,从而可以继续执行。(这里 A--->B 为什么是 dotted edges 而 B->A 则是 solid edges 呢?这是因为 A 已经执行成功了 update c1=3,所以 B 需要等待 A 的 transaction lock,所以是 solid edge,而 B 的 update 并没有执行成功,在 segment1 上面 A 和 B 都在等待 tuple lock 而未更新,所以 A 的 update c1=1 到 B 是 dotted edge,这是可以使 B 释放锁,让 A 拿锁执行成功。 )
# *2. DISTRIBUTED TRANSACTION MANAGEMENT*
在 GP 中,coordinator 节点执行时会分配一个分布式的事务 id,就是一个单调递增的整数,每个 segment 也有一个对应的 local 的事务标记,这里就存在一个从 segment 本地的事务 id 到分布式事务 id 的一个映射。每个 segment 也会生成一个本地的快照,而 coordinator 节点持有的分布式快照有一个进行中的分布式事务 id 列表和已提交的最大的事务 id 组成。
在 MVCC 执行时需要判断 tuple 的可见性,首先判断本地可见性,就是通过本地的事务 id 和当前 tuple 的 snapshot 来判断可见性,然后通过本地的事务 id 来找到映射的全局事务 id,全局事务 id 通过与分布式的快照来比较确定当前事务的全局可见性。
对于已经这个映射关系,只需要保留 snapshot 上正在运行的可以看到的最老的事务对应的映射关系即可。
对于只需要一个 segment 执行的事务可以使用 One phase commit,这样可以减少一次 prepare 的 round-trip 以及在 segment 上 prepare 和在 coordinator 上 commit 的文件 sync 操作。
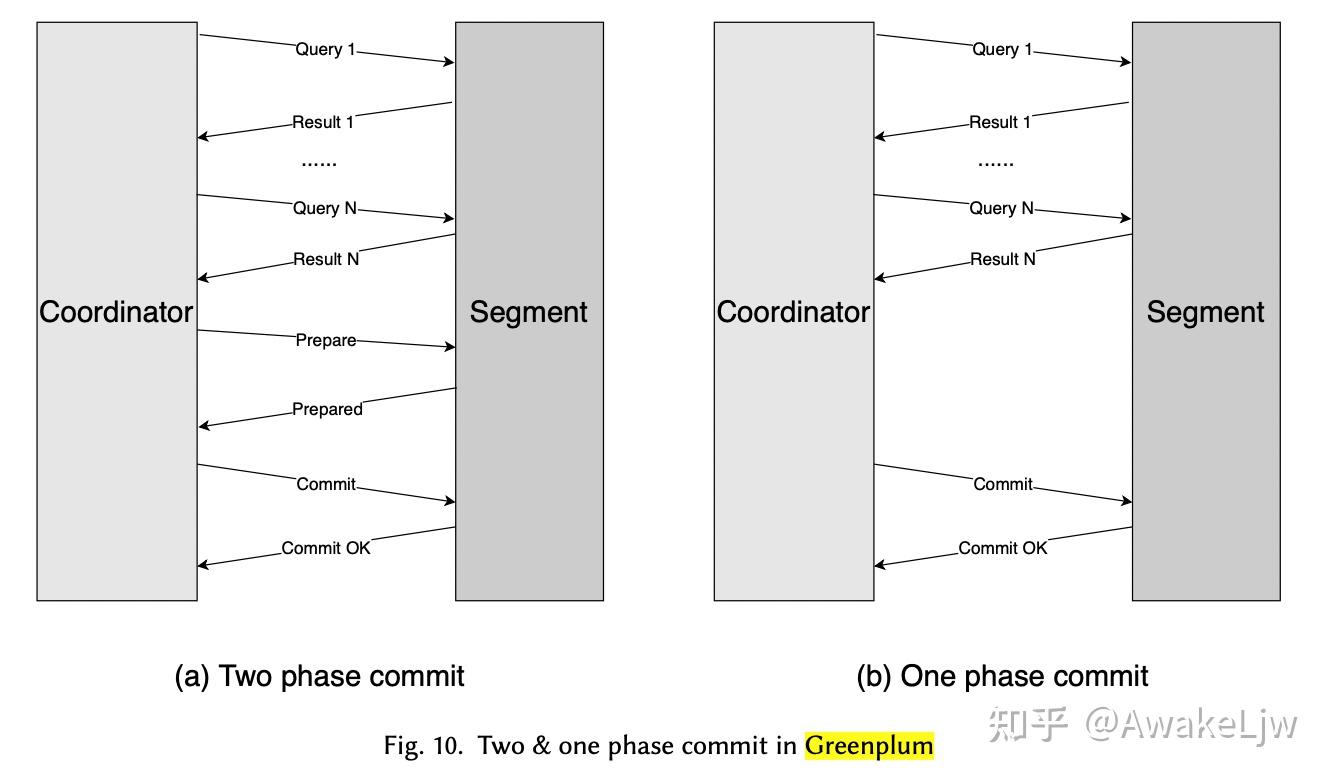
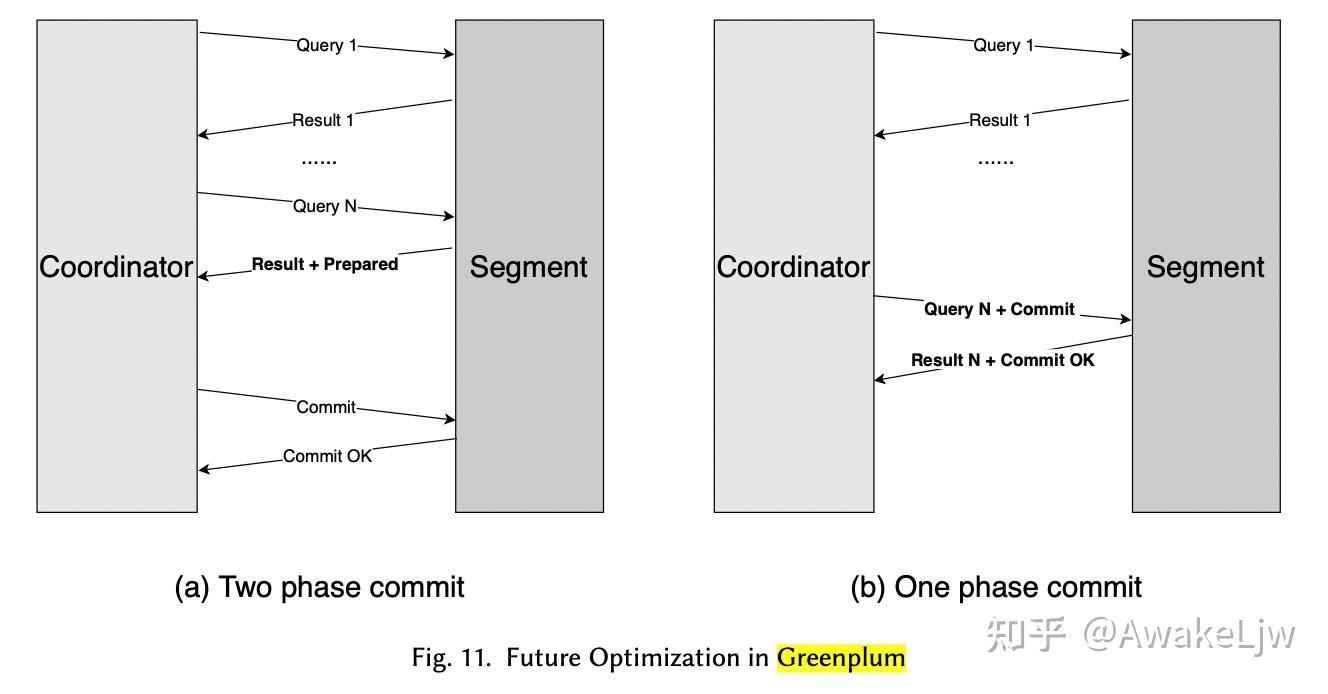
进一步的可以在最后一次 query 执行时由 segment 来执行 prepared 操作,而不需要 coordinator 来提醒,同理在单相提交时也可以在最后一个 query 中加入 commit 指令,减少一次 roundtrip。
# *4. RESOURCE ISOLATION*
不像 TiDB 一样,将 AP 和 TP 完全在物理上隔离开,GP 的 AP 和 TP 在可能在相同的 segment 执行,所以需要处理资源竞争的问题。主要的竞争资源包括 cpu 和内存。GP 通过 resource group 来逻辑上隔离 AP 和 TP 的资源分配。
CPU 资源隔离是通过 cgroup 实现的,cgroup 可以限制和隔离进程集合的 cpu 资源使用。cgroup 的每个资源组中的配置可以通过 cpu.shares 和 cpuset.cpus 来设置。cpu.shares 是个软限,控制 cpu 使用的百分比和优先级。cpuset.cpus 是硬限,控制资源组内的 cpu 的核数。
内存资源的隔离是基于内存管理模块 Vmemtracker。
内存资源是一种 hard resource,也就是一旦申请,不能立刻回收,当内存使用超过上限就只能 cancel query。GP 使用三个层次的内存分配来管理内存的使用。
- slot memory,用来控制一个 resource group 中单个 query 的内存使用,计算方法是改资源组内的非共享内存 / 并发数。
- group shared memory,当同一个资源组中的某一个 process 的 slot 内存不够用时,可以来这里申请, 这层内存可以通过 MEMORY_SHARED_QUOTA 来配置。
- Global shared memory, 这是最后一层,是所有 resource group 共享的内存
如果以上内存仍然不能满足当前 query 的内存使用,就只有 cancel 了。
资源组的配置如下:可以按 role 来分配资源组。
CREATE RESOURCE GROUP olap_group WITH (CONCURRENCY=10, MEMORY_LIMIT=35, MEMORY_SHARED_QUOTA=20, CPU_RATE_LIMIT=20);
CREATE RESOURCE GROUP oltp_group WITH (CONCURRENCY=50, MEMORY_LIMIT=15, MEMORY_SHARED_QUOTA=20, CPU_RATE_LIMIT=60);
To isolate the resources between different user groups, DBA could assign a resource group to a role using the ALTER ROLE or CREATE ROLE commands. For example:
CREATE ROLE dev1 RESOURCE GROUP olap_group; ALTER ROLE dev1 RESOURCE GROUP oltp_group;
2
3
4
在分析性负载中,内存分配更多;而事务型负载 cpu 资源分配更多。AP 的并发数限制相对较小,是因为内存分配有限,防止并发过大美哥 slot 内存更小,导致频繁的下盘。GP 计划引入内存预测的方法来高效使用内存,而不受并发数的限制。
# *COMCLUSION*
Greenplum 提供了一种有 OLAP 转换到 HTAP 的思路,通过一阶段提交和 GDD 来提升 OLTP 的性能,通过资源隔离减少 AP 对 TP 的资源竞争。与 TiDB 相比,GP 在资源的隔离上需要花费更多的经历。而 GP 的分布式执行能力使得它在 AP 上有更好的表现。
# *appendix*
NETWORK DEADLOCK IN GREENPLUM
greenplum 的 motion 算子使用的是 UDP 连接,为了使连接可靠,所以 receiver 需要返回 ACK 给 sender。所以这造成了两种等待事件:1,receiver 等待 sender 发送数据;2,sender 等到 receiver 返回 ACK。
CREATE TABLE t1(c1 int, c2 int);
CREATE TABLE t2(c1 int, c2 int);
INSERT INTO t1 SELECT i,i FROM generate_series(1, 100)i; INSERT INTO t2 SELECT i,i FROM generate_series(1, 100)i;
EXPLAIN SELECT * FROM t1 JOIN t2 on t1.c2 = t2.c2;
QUERY PLAN
-----------------------------------------------------------
Gather Motion 3:1 (slice3; segments: 3)
-> Nested Loop
Join Filter: (t1.c2 = t2.c2)
-> Redistribute Motion 3:3 (slice1; segments: 3)
Hash Key: t1.c2
-> Seq Scan on t1
-> Materialize
-> Redistribute Motion 3:3 (slice2; segments: 3)
Hash Key: t2.c2
-> Seq Scan on t2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
对于上述计划,slice2 是对内表做重分布,slice1 是对外表进行重分布,
简单的说就是 segment0 中的 join slice 在等内表对应的数据,另一个 segment 上的 join slice 在等外表的数据。而他们都因为无法返回 ACK 导致对应的对应的 send buffer 无法继续发送。
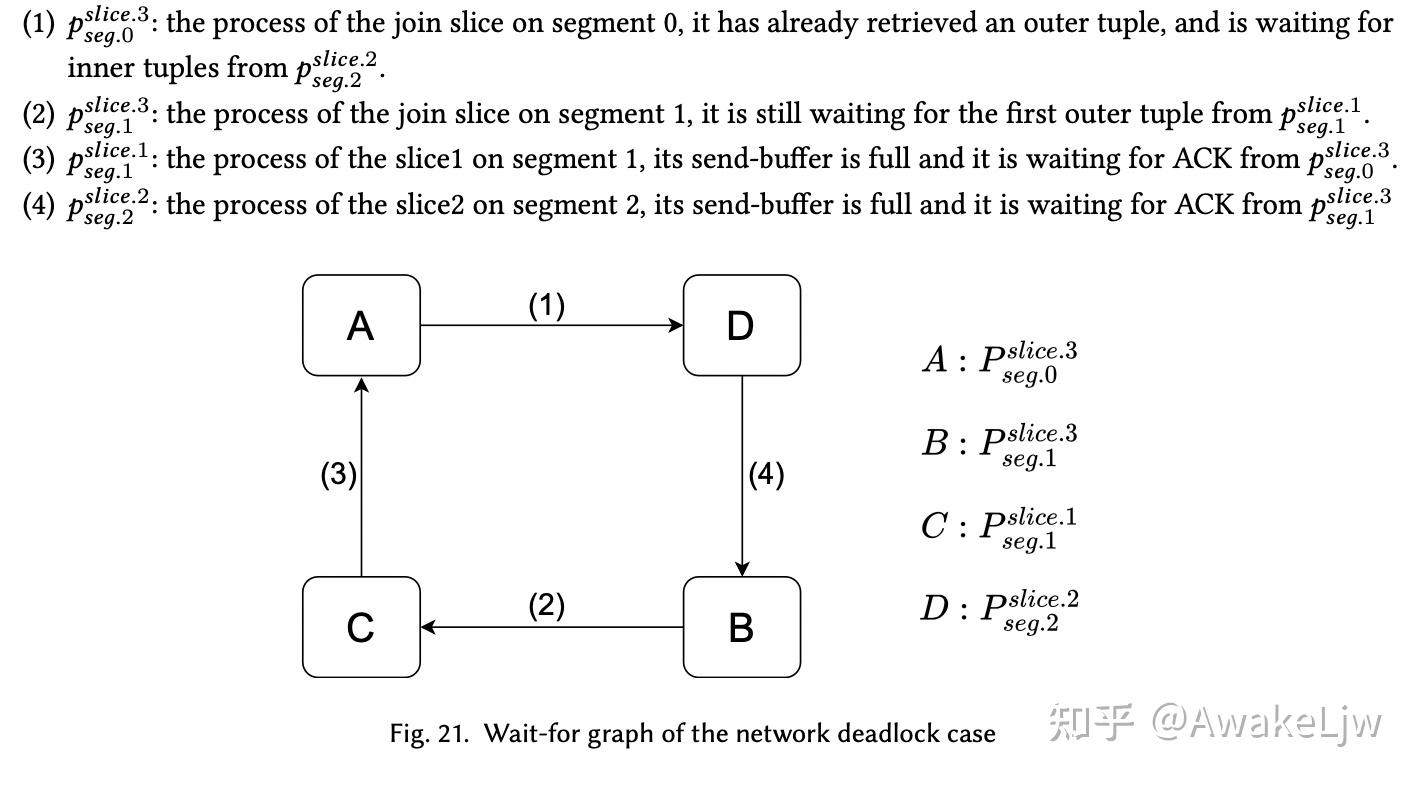
GP 的解决方法就是先把内表全部无花完在移动外表,防止内外表同时移动,导致单个 segment 上的 join 无法完成从而引起网络死锁。
全文完
本文由 简悦 SimpRead (opens new window) 优化,用以提升阅读体验
使用了 全新的简悦词法分析引擎 beta,点击查看 (opens new window)详细说明
Greenplum: A Hybrid Database for Transactional and Analytical Workloads (opens new window)1. GREENPLUM‘S MPP ARCHITECTURE (opens new window)2. LOCK OPTIMIZATION (opens new window)2. DISTRIBUTED TRANSACTION MANAGEMENT (opens new window)4. RESOURCE ISOLATION (opens new window)COMCLUSION (opens new window)appendix (opens new window)