跟着 LevelDB 学 C++,跟着 Rocksdb 学引擎。看完这一篇,你会对这一句话有更加深刻的理解。
LevelDB 能够教给你关于 C++ 语言本身很多的知识,如何写好 C++ 代码,如何让你掌握面向对象的核心编程思想。而 Rocksdb 则会交给你足够多的系统知识,优秀的存储引擎需要对上层应用以及底层的操作系统有非常深入的了解,这样我们才能够通过引擎提供足够的可靠性 / 易用性的同时 将操作系统 以及 底层硬件性能发挥到极致。
下面提到的关于 Rocksdb 的链路优化可能之前的博文中已经描述过了, 会做一个概览描述。
# 1. 读链路
# 1.1 FileIndexer
对于 LSM-tree 的 Get 链路 会执行如下的一些搜索过程:
memtable::Get` --> `immutable::Get` --> `table->Get
在前面的部分,如果拿到了 key-value 那就直接返回,拿不到,就每一步执行。对于 table->Get的逻辑,其实就是从 sst 中读,读到的结果会 load 到 block_cache,读的过程则是 按照LEVEL 进行。L0因为是 tierd compaction 策略,LSM-tree 允许其有重叠 key,则需要在每一个文件中进行查找;如果没找到,则对大于 L0 的文件,按层查找。
我们要讨论的FileIndexer的主要功能是 Rocksdb 对于这个查找过程的优化,介绍 Rocksdb 的查找过程之前,我们肯定是先需要了解一下 LevelDB 的查找逻辑。
# 1.1.1 LevelDB sst 查找实现
对于 LSM-tree 来说,生成的每一个 sst 文件都会在内存中维护一个 FileMeta,存放在这个 sst 对应的 version 之中。
FileMeta数据结构如下:
struct FileMetaData {
FileMetaData() : refs(0), allowed_seeks(1 << 30), file_size(0) {}
int refs;
int allowed_seeks; // Seeks allowed until compaction
uint64_t number;
uint64_t file_size; // File size in bytes
InternalKey smallest; // Smallest internal key served by table
InternalKey largest; // Largest internal key served by table
};
2
3
4
5
6
7
8
9
10
因为 key 在单个 sst 文件中是有序的, 所以 FileMeta 中只需要保存关键的smallest和largest即可,这两个变量也是我们文件查找过程的关键。
因为 L0的每一个文件都要查找,那就需要看当前 key 是否在每一个 sst 文件的 range 中。
tmp.reserve(files_[0].size());
for (uint32_t i = 0; i < files_[0].size(); i++) {
FileMetaData* f = files_[0][i];
if (ucmp->Compare(user_key, f->smallest.user_key()) >= 0 &&
ucmp->Compare(user_key, f->largest.user_key()) <= 0) {
// user key在当前 file中,则添加当前file 到数组中
tmp.push_back(f);
}
}
2
3
4
5
6
7
8
9
对大于L0的文件,LevelDB 这里做的是整层进行二分查找,找到文件之后返回文件的 id 即可。
int FindFile(const InternalKeyComparator& icmp,
const std::vector<FileMetaData*>& files, const Slice& key) {
uint32_t left = 0;
uint32_t right = files.size();
while (left < right) {
uint32_t mid = (left + right) / 2;
const FileMetaData* f = files[mid];
if (icmp.InternalKeyComparator::Compare(f->largest.Encode(), key) < 0) {
// Key at "mid.largest" is < "target". Therefore all
// files at or before "mid" are uninteresting.
left = mid + 1;
} else {
// Key at "mid.largest" is >= "target". Therefore all files
// after "mid" are uninteresting.
right = mid;
}
}
return right;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
二分本身的比较逻辑是 O(logn) 的时间复杂度,对于 LSM-tree 来说,实际大数据量的情况下大多数的文件是存储在最底层。加入 L1=256M,到第五层的时候是 2T,每一个文件 64M 来算,到第五层会有接近 4w 个文件,那随机查找的时候,每一个 Get 大多情况下都会落到最后一层,也就意味着从 L0-->L5 至少 20 次的比较,对 cpu 来说可谓是一个非常大的负担了。
rocksdb 这里利用文件有序这个特性来尝试减少 整层二分比较的次数。
# 1.1.2 Rocksdb FileIndexer 实现
L0 每一个文件的查找还是避免不了,如果 user_key 在 L0 某一个文件的 range 内又不在这个文件中,这里 rocksdb 会基于当前文件 通过 FileIndexer 构造其接下来要查找的下一层文件的文件 range。
我们详细看看 FileIndexer 具体会做一些什么:
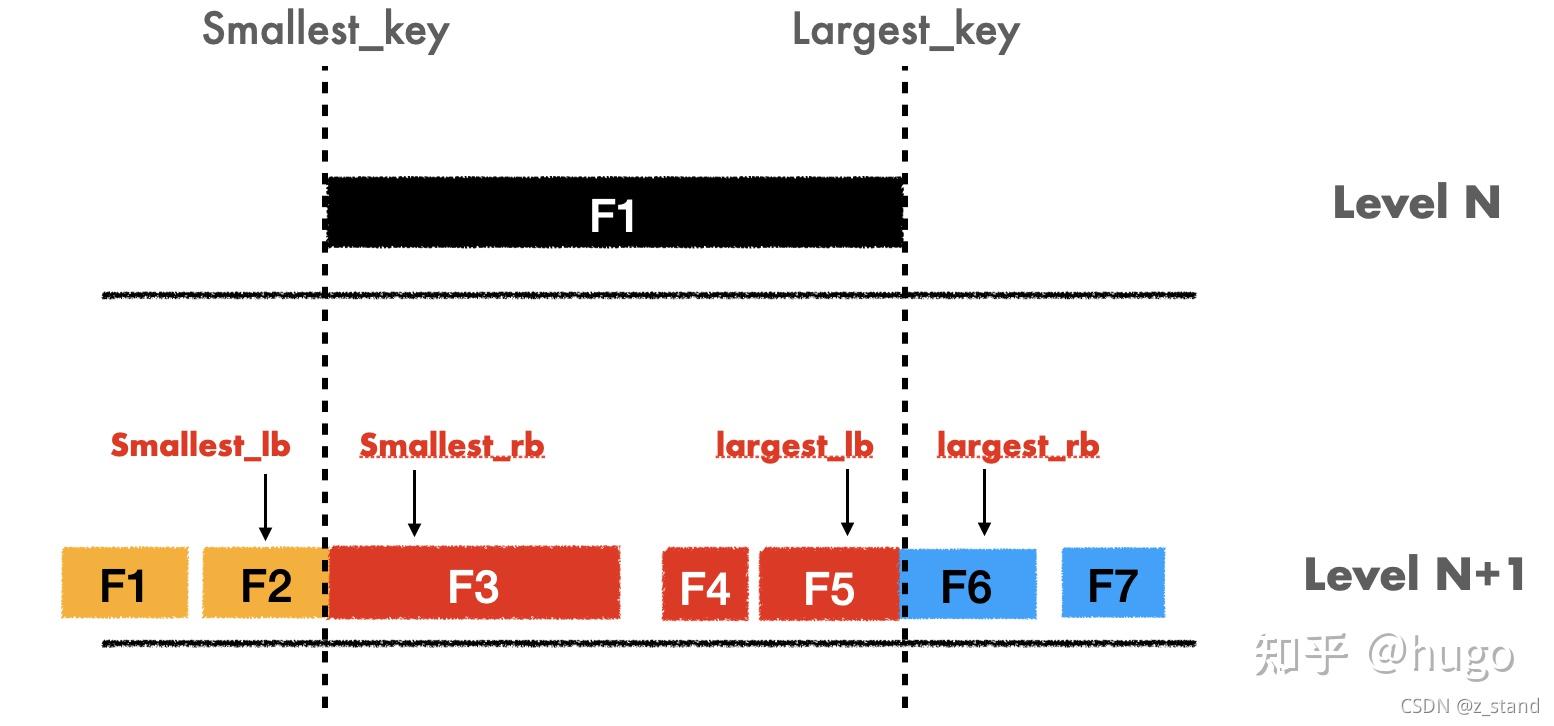
拿着LN 文件的smallest_key 和 largest_key,构造其 IndexUnit,也就是四个变量:
smallest_lb,smallest_key 的左边界最有可能包含 F1 range 内 的 文件编号smallest_rb,smallest_key 的右边界 最有可能包含 F1 range 内 的 文件编号largest_lb,largest_key 的左边界 同上largest_rb, largest_key 的右边界 同上
因为大于 L0 的文件会整层都不会有 key-range 重叠,我们的 user_key 假如落在了 F1 上,那就可以根据上面的四个变量来划分接下来在LN+1的文件的查找区间。
比如:
1. user_key < smallest_key
smallest_lb=1 查找的file_range [0,1],如果F1的文件编号就是0,那smallest_lb 也就是0了。
2. user_key > smallest_key && user_key < largest_key
smallest_rb=2;largest_lb=4 查找的file_range [2,4],也就是在smallest_rb和largest_lb之间
3. user_key > largest_key
largest_rb=5, 查找的file_range 会在[6,7]之间
2
3
4
5
6
大多数的查找场景中,当我们 user_key 锁定LN的一个 file_range 的时候,这个 user_key 大概率是在LN+1的 [smallest_rb,largest_lb] 的 range 之间。
可以看到,我们有了每一个文件的 FileIndexer,这样就能够在查找的过程中极大得减少比较的次数。这种 FileIndexer 的查找过程 key 之间的比较次数完全是可控的 l,对于 Ln 的一个文件,在 Ln+1 中 key_range 的放大系数为 10,也就是平均只需要 log10 = 3 次比较。相比于 LevelDB 的整层二分查找,尤其是在最后一层的十几次比较,可以说是极大得减少了文件查找所需要的 CPU。
当然,这里需要注意的是 FileIndexer 的构造也需要消耗一定的 CPU。
构造部分的逻辑会每一次有新的 sst 文件生成的时候 以及 DB 重启 的时候触发:
- DB 重启,
Recover的时候调用Version::PrepareApply来进行构造 - Compaction/Flush 完成之后 :
// Flush 完成之后
TryInstallMemtableFlushResults
LogAndApply
ProcessManifestWrites
PrepareApply
GenerateFileIndexer
// Compaction完成之后
BackGroundCompaction
LogAndApply
ProcessManifestWrites
PrepareApply
GenerateFileIndexer
2
3
4
5
6
7
8
9
10
11
12
构造 Indexer 的过程肯定会拖慢整个 Flush 或者 Compaction 的效率,但是他们是后台线程,且触发的次数相比于我们实际 workload 下的 read-heavy 来说实在是微不足道,那通过这一点构造时候的 CPU 消耗来极大得减少我们 read-heavy 时的 CPU 消耗,还是非常值的。
# 1.2 PinnableSlice 减少内存拷贝
先来看一下 LevelDB 的 Get 接口:
Status Get(const ReadOptions& options, const Slice& key,
std::string* value) override;
2
这个std::string的 value 变量在后续从 sst 中读到数据之后会复制拷贝到这个 value 变量中。
struct Saver {
SaverState state;
const Comparator* ucmp;
Slice user_key;
std::string* value; // 后续要返回给用户的变量
};
} // namespace
static void SaveValue(void* arg, const Slice& ikey, const Slice& v) {
Saver* s = reinterpret_cast<Saver*>(arg);
ParsedInternalKey parsed_key;
if (!ParseInternalKey(ikey, &parsed_key)) {
s->state = kCorrupt;
} else {
if (s->ucmp->Compare(parsed_key.user_key, s->user_key) == 0) {
s->state = (parsed_key.type == kTypeValue) ? kFound : kDeleted;
if (s->state == kFound) {
// 内存拷贝
s->value->assign(v.data(), v.size());
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这个时候就会发生内存拷贝。
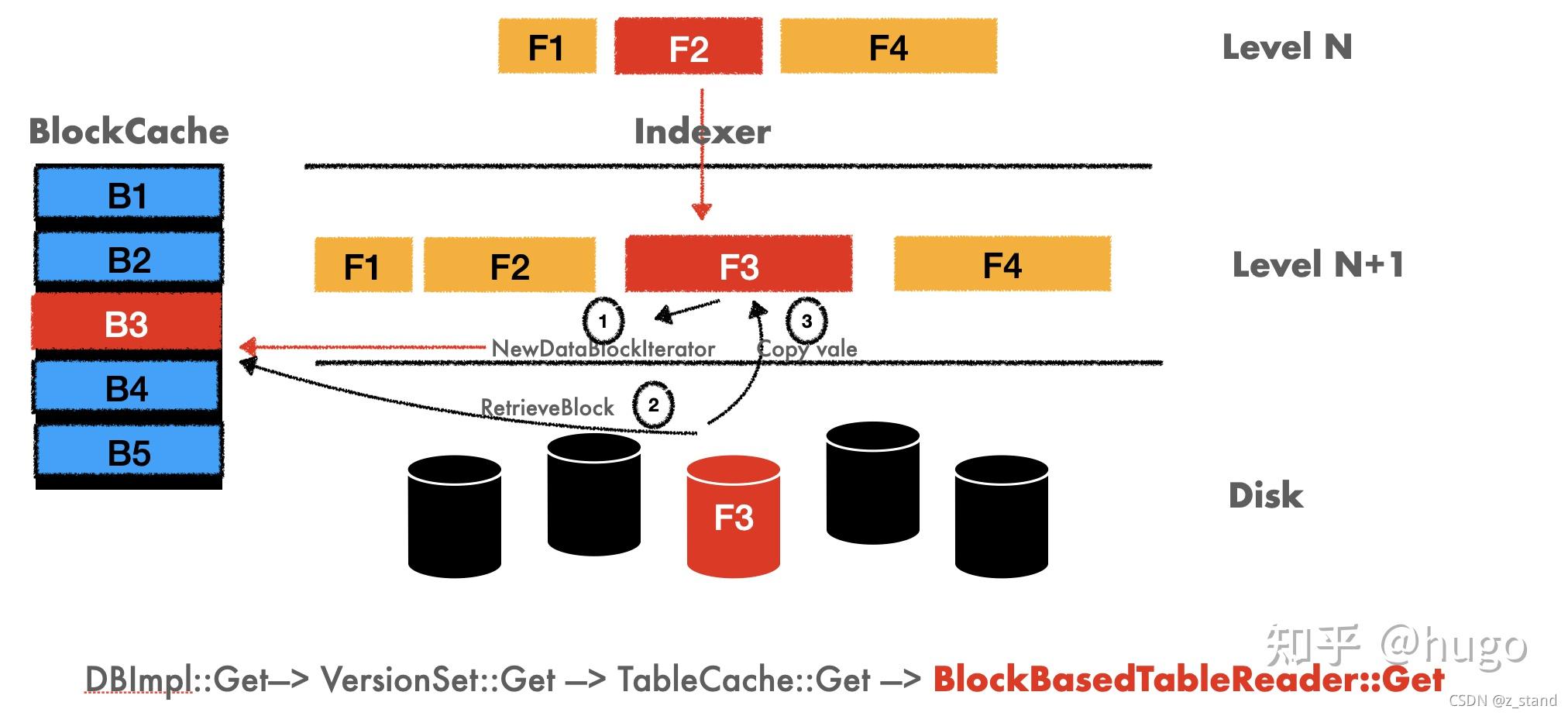
上图就是 Rocksdb 在早期版本的实现,也就是 leveldb 的 std::string 透传到底层,通过内存拷贝拿到数据之后再返回给用户。
内存拷贝涉及到数据从旧的地址中搬移到新的地址,那这个过程会申请新的内存,释放旧的内存。尤其是在我们读 heavy 且实际数据量远超内存的场景下,频繁申请内存 / 释放内存 (内核缺页 -》回收页面 --》分配新页面) 以及 数据的拷贝对 内存以及 CPU 都是不小的负担,这个痛点也是所有做底层软件需要尽可能避免的问题。(当然,前提是其他的数据结构 / 存储上的 优化已经足够细致了,瓶颈可能会在这里)
那现在版本的 Rocksdb 为了追求极致性能,肯定会对这一部分进行优化的。
直接看下图:
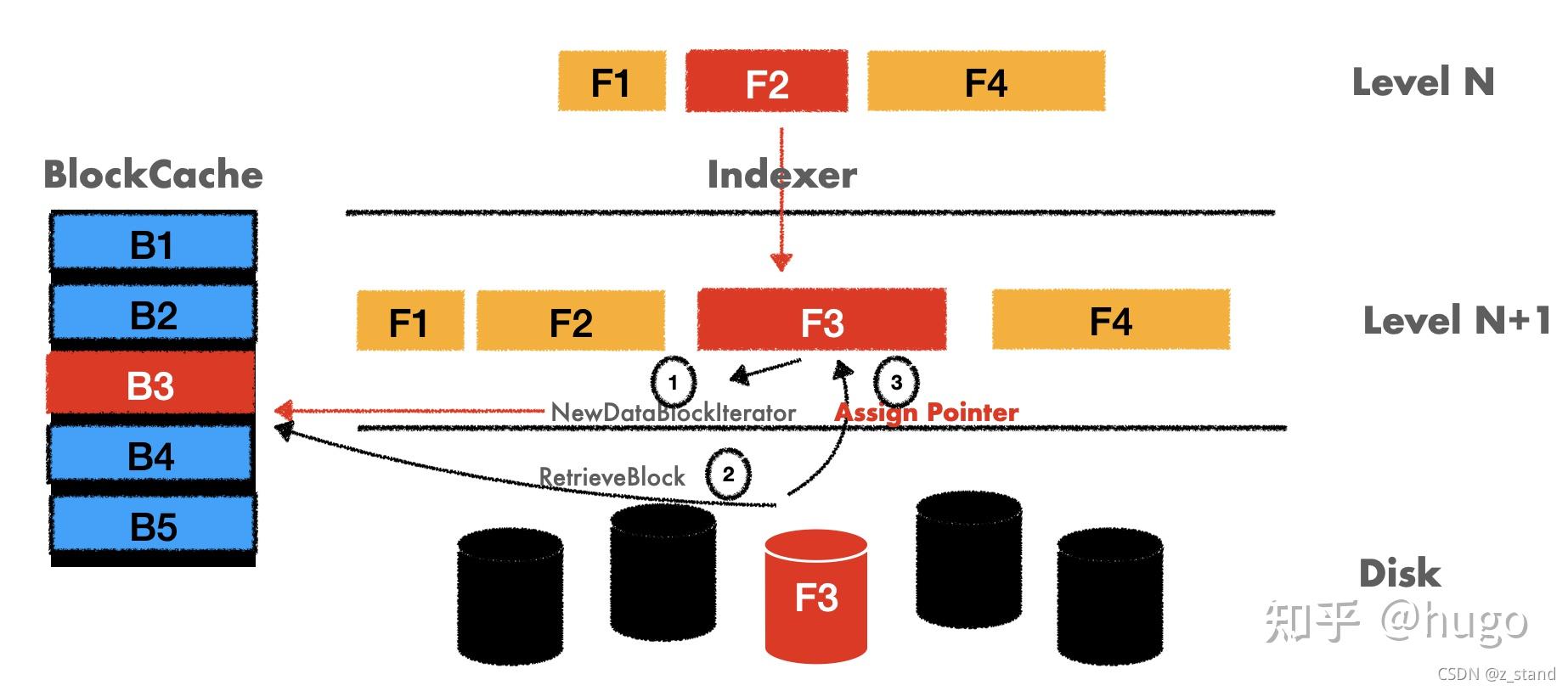
Rocksdb 这里优化的部分就是在第三步的时候 从 sst 中拿到 BlockContents 之后 不会直接将其中的 value 填给用户传下来的变量,而是将拿到的这个 value 的地址给这个变量。
这里我们会从逻辑中发现一个潜在的问题,实际填充给用户的是读上来的 value 的地址。逻辑如下:
BlockBasedTable::Get
BlockBasedTable::NewDataBlockIterator // 构造DataBlockIter
GetContext::SaveValue // 将DataBlockIter 的value内容填充给用户
2
3
但是 BlockBasedTable 通过 DataBlockIter 拿到的 value 结果是要填充给 BlockCache 的。那填充完成之后当前的 DataBlockIter 是需要被释放的,释放则意味着用户拿到的地址空间就不存在了。
有没有办法让这个 DataBlockIter 的释放能够延迟一段时间,到上层 Get 用户已经取到了这个 value 之后再释放呢。
来看一下 rocksdb 使用的获取实际 value 的类 PinnableSlice 以及 能够延迟 DataBlockIter 生命周期的类Cleanable。
对于PinnableSlice来说继承Slice,也就能够通过data_来缓存实际数据。它提供了一系列基于Cleanable类的成员函数实现的函数。所以,我们主要看一下Cleanable这个类是如何让 PinnableSlice 拿到的地址延迟释放呢。
class PinnableSlice : public Slice, public Cleanable {
......
}
2
3
Cleanable 类的成员如下:
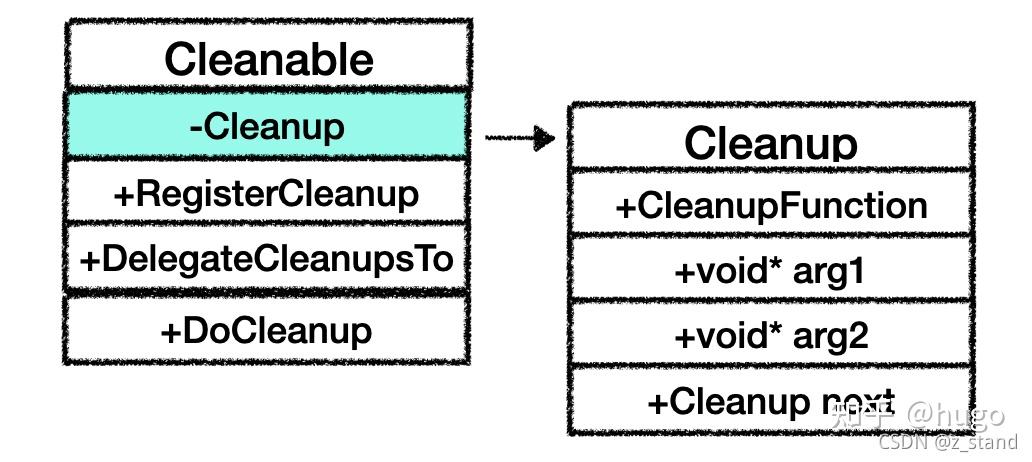
其中的私有成员主要是维护了一个Cleanup类,这个类用来保存执行具体逻辑的部分,包括函数指针以及两个参数,同时还维护了一个单链表。
那我们具体看看Cleanable类的成员函数 之间是如何和Cleanup一起延长一个类的生命周期的。
void Cleanable::RegisterCleanup(CleanupFunction func, void* arg1, void* arg2) {
assert(func != nullptr);
Cleanup* c;
if (cleanup_.function == nullptr) {
c = &cleanup_;
} else {
c = new Cleanup;
c->next = cleanup_.next;
cleanup_.next = c;
}
c->function = func;
c->arg1 = arg1;
c->arg2 = arg2;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
可以看到在 RegisterCleanup 中,将需要 register 的函数指针和参数 创建一个新的Cleanup对象,添加到当前Cleanable类的cleanup_之前。
大体过程如下图:
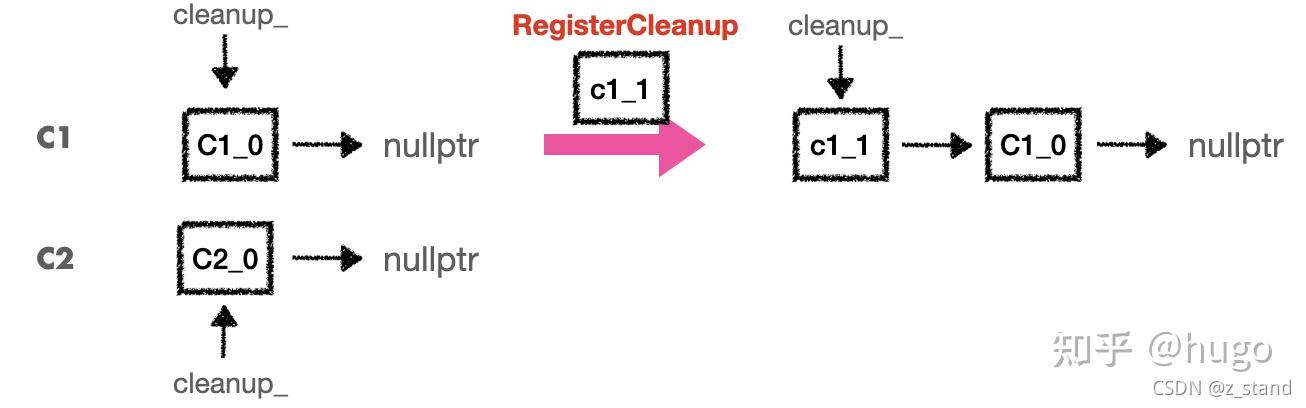
有两个Cleanable对象,如果 C1 想要注册一个 cleanup 对象,传入函数指针和参数,那就会构造一个新的 cleanup 对象,使用链表头插法插入到 C1 维护的 cleanup 对象链表中。
在 Cleanable 对象析构的时候可以调用它的析构函数,执行DoCleanup逻辑
Cleanable::~Cleanable() { DoCleanup(); }
执行如下函数的逻辑:
inline void DoCleanup() {
if (cleanup_.function != nullptr) {
(*cleanup_.function)(cleanup_.arg1, cleanup_.arg2);
for (Cleanup* c = cleanup_.next; c != nullptr;) {
(*c->function)(c->arg1, c->arg2);
Cleanup* next = c->next;
delete c;
c = next;
}
}
}
2
3
4
5
6
7
8
9
10
11
按照顺序遍历链表,执行 cleanup 对象中的函数,从头执行到尾巴。
如果将 Cleanable 对象 C1 通过DelegateCleanupsTo委托给 C2,我们看看会发生什么:
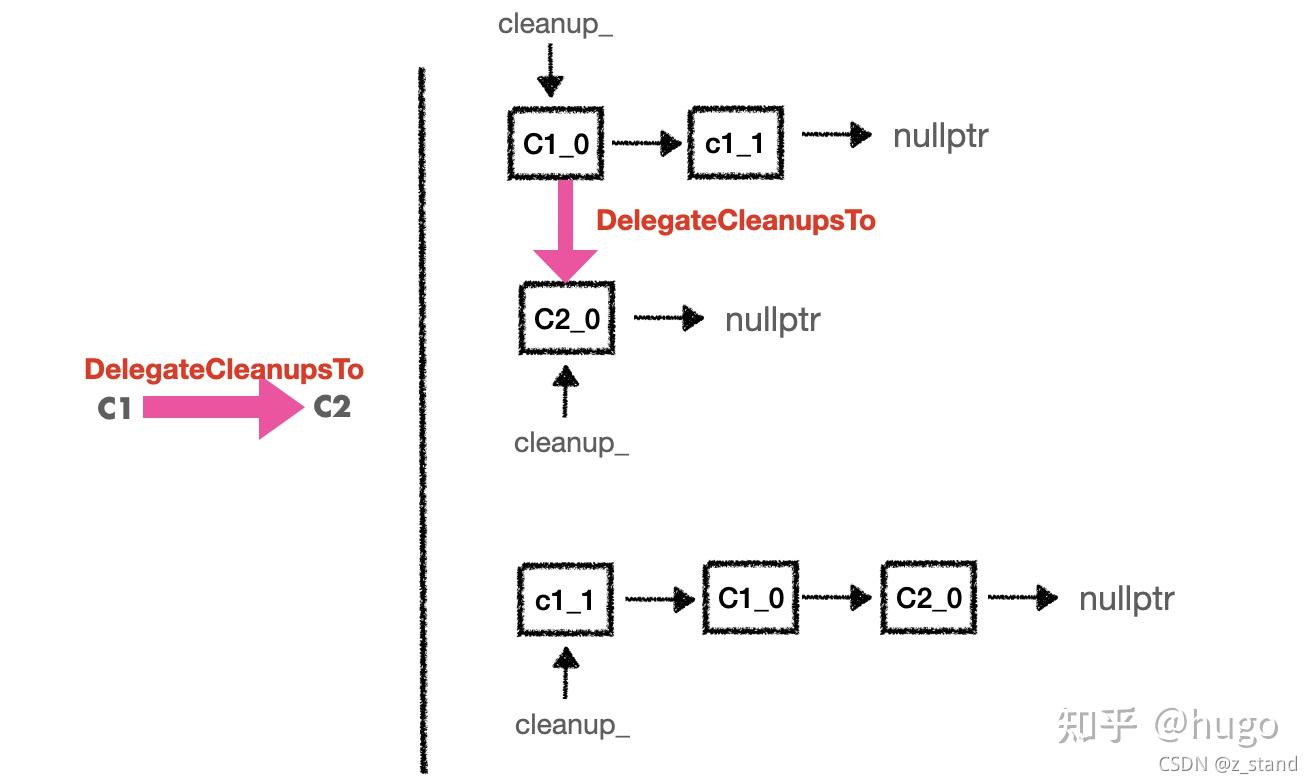
大体的过程就是将 C1 对象中的 cleanup 对象逐个取出来,头插法插入到 C2 维护的 cleanup 对象的链表中。
这样,C1 委托给 C2 之后,C2 在最后析构的时候就按照顺序执行所有的 C1 的资源释放逻辑,是不是非常巧妙。
void Cleanable::DelegateCleanupsTo(Cleanable* other) {
assert(other != nullptr);
if (cleanup_.function == nullptr) {
return;
}
// 先将当前的cleanup 成员 转交给other
Cleanup* c = &cleanup_;
other->RegisterCleanup(c->function, c->arg1, c->arg2);
c = c->next;
// 如果cleanup链表还有成员,则逐个遍历,挨个转交
while (c != nullptr) {
Cleanup* next = c->next;
other->RegisterCleanup(c);
c = next;
}
// 最后清理当前对象
cleanup_.function = nullptr;
cleanup_.next = nullptr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
我们可以看一个简单的 Cleanable 类的使用方式,如下测试代码:
void Multiplier(void* arg1, void* arg2) {
int* res = reinterpret_cast<int*>(arg1);
int* num = reinterpret_cast<int*>(arg2);
*res *= *num;
}
int main() {
int n2 = 2;
int res = 1;
{
Cleanable c2;
{
Cleanable c1;
c1.RegisterCleanup(Multiplier, &res, &n2);
c1.DelegateCleanupsTo(&c2);
}
// ~Cleanable c1 ,res = 1
std::cout << "Delete c1, res is : " << res << std::endl;
}
// ~Cleanable c2 , res = 2
std::cout << "Delete c2, res is : " << res << std::endl;
}
// output
Delete c1, res is : 1
Delete c2, res is : 2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
当执行 C2 的析构的时候 才会执行 Multiplier 中的逻辑,因为 C1 将注册的 Multiplier 转交给了 C2,如果没有转交,则第一个输出的内容就是 2 了。
通过 Cleanable 对象的特性,我们回到解决内存拷贝问题中的 PinnableSlice 中,就可以让 DataBlockIter 和 PinnbaleSlice 都继承 Cleanable类,这样在将 DataBlockIter 的地址交给 PinnableSlice 的时候就可以将其释放逻辑也转交给 PinnableSlice,用户层拿到了想要的 value 之后 析构 PinnableSlice 的时候再释放 DataBlockIter 就好了。
这里的地址赋值 以及 转交逻辑如下:
BlockBasedTable::Get
GetContext::SaveValue //构造好的DataBlockIter 的 value 地址进行传入进去
PinSlice
2
3
最终的转交链路如下:
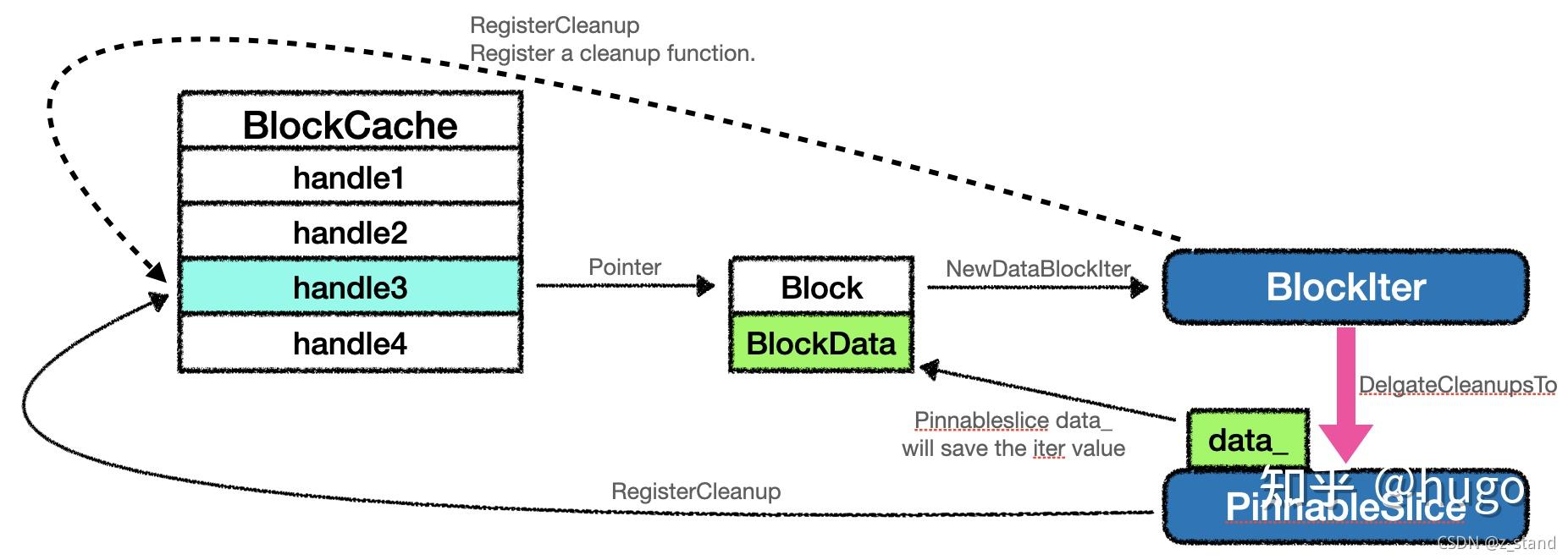
BlockIter 和 PinnableSlice 都是继承了 Cleannable 类,他们在初始化的时候都会注册一个自己释放空间的逻辑,在通过迭代器读取到了数据之后会将 BlockIter 委托给 PinnableSlice 对象,委托的过程就是让 PinnableSlice 的 data_指针指向 BlockData 的地址。
# 1.3 Cache
# 1.3.1 LRU Cache
Rocksdb 工业级 LRU Cache 实现 (opens new window)
# 1.3.2 Clock Cache
LRU Cache 在并发场景并不是很友好,所以 Rocksdb 推出了 clock cache,在高并发下更加有优势。
先看一下 Clock Cache 的大体架构图:
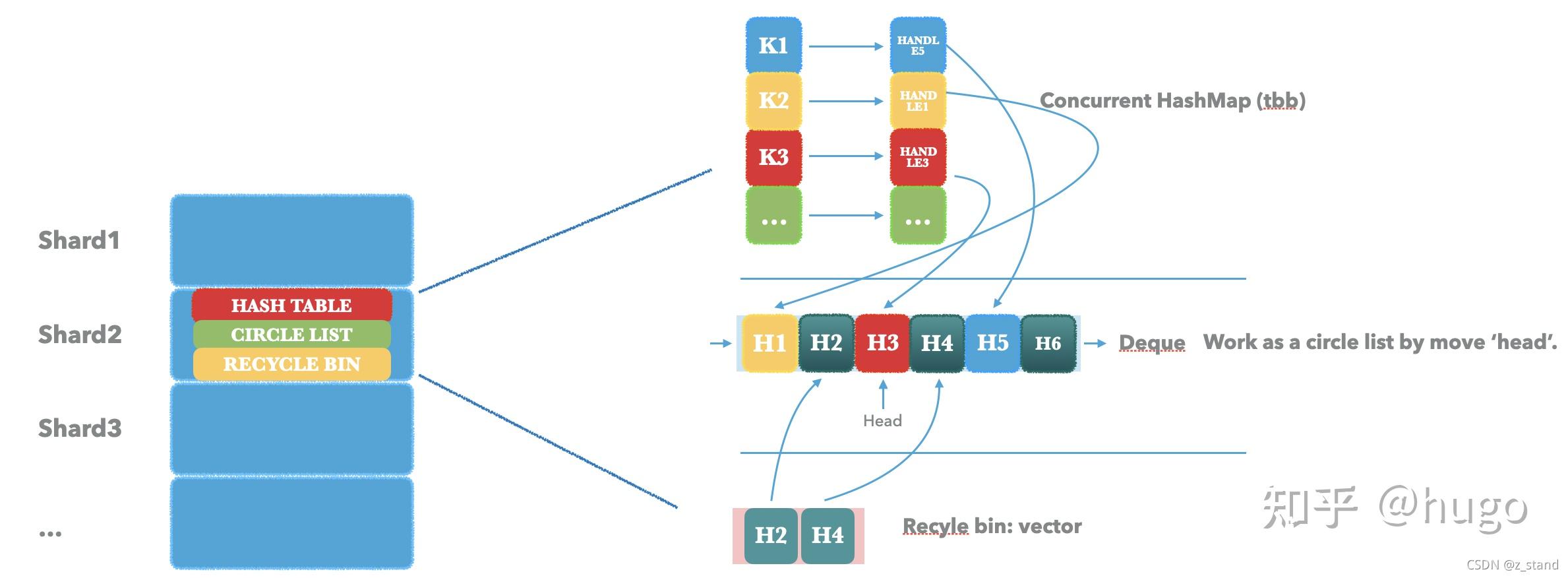
Clock Cache 同样是分 shard,外部做了一层 hash,基本组件如下:
- Concurrent HashMap,用来缓存 key 以及 value-handle。这里为了对并发友好一些,hashmap 使用的是 TBB 的 concurrent_hash_map
- Circle List,这个数据结构主要是为 实现 clock 算法用的。Rocksdb 这里使用的是 Deque + head 索引实现环形链表的功能。即通过 head 进行 deque 的遍历, 遍历的过程中遍历到 deque 的末尾的时候让 head 重新指向 deque 的头部。
- Recycle bin,一个保存从 Deque 中淘汰节点的数组。用于后续有新的节点加入的时候先从 recycle bin 中直接取可以插入的位置即可,不需要重新申请存储空间。
Clock 算法的淘汰原理就是针对存储在环形链表中的每一个节点维护两个属性: Access 和 Modify,当 clock cache 满了之后需要进行节点的淘汰, 这个时候会循环遍历环形链表,发现每个节点的两个属性满足以下要求时就进行淘汰。
- A = 0 ,M = 0; 即没有被访问过,也没有被修改过,则优先淘汰。
- A = 0,M = 1; 没有被访问过, 被修改过,则第一次遍历会将这个属性置为 0,第二次遍历遇到这种情况就可以直接被淘汰。
- A = 1, M = 0; 被访问过,没有被修改过,则第一次遍历同样会将访问过的属性置 0, 第二次遍历再进行清理。
- A = 1, M = 1; 被放过,也被修改过。第一次遍历不会被淘汰。
淘汰的时候会优先选择淘汰第一种情况,对第二种情况进行置位以便下次淘汰,对第三和第四种情况进行访问计数自减,知道访问计为 0 的时候才会淘汰。
而 rocksdb 实现的 ClockCache 的算法大体接近,只是多了一些属性(incache, usage, reference_count )只有当 reference_count=1 且 incache=1 时才会进行淘汰,否则淘汰的时候会将这一些属性的计数自减。
Clock Cache 相比于 LRUCache 的优势主要有以下两种:
- ClockCache 的节点淘汰并不会直接从 环形链表中删除释放节点,而是将淘汰的节点放在 Recycle bin 数组中,不像 LRU cache 的淘汰需要操作双向链表的删除以及节点释放。
- ClockCache 在 Erase 的时候,可以使用 tbb-hashtable 的 并发 erase 优势。
但是 ClockCache 在 insert 的时候也会加锁,所以 cache insert 部分的优势相比于 Lru 基本没有,lookup 的时候是无锁的(不涉及数据结构的变更,不需要加锁),所以整体上来看 ClockCache 在 lookup 以及 erase 的比例比较高的时候性能是比 LRU cache 有优势的,但是 insert 比例比较高的时候基本就没有什么优势了。
使用cache_bench 工具进行测试可以比较明显得看到这两种 Cache 在不通 workload 下的性能差异:
- Insert 80%, lookup 10%, erase 10%, threads 32, shards 32;
LRU : 305w/s, Clock: 203w/s
- Insert 10%, lookup 10%, erase 80%, threads 32, shards 32;
LRU: 697w/s, Clock: 1173w/s
- Insert 10%, lookup 80%, erase 10%, threads 32, shards 32
LRU: 681w/s, Clock: 1137w/s
当然,实际应用过程中对 cache 的操作是一个复杂过程,与 workload 强相关,比如 Put 比例多且 cache 大小远小于实际的磁盘数据量时,则 cache 的 insert 比例都会比较高(compaction 导致的 cache 失效回填),而且这种情况下的 Get 的 key_range 也是完全随机的话 lookup 和 insert 比例都会比较高。而对于热点场景,大多数是 lookup 的情况可能 Clockcache 会更有优势一些。
# 1.4 ThreadLocalPtr 线程私有存储
线程私有存储是 Rocksdb 为 version 系统推出的一种访问模型,能够最大程度得实现无锁访问,从而加速整个引擎的读 / 写 / compaction 的效率。了解线程私有存储之前我们需要先了解一下 Rocksdb 的 version 系统,从而能够整体看一下 Rocksdb 的 key/value 的读写操作模型。
# 1.4.1 version 系统
整个 version 系统的架构及关系图如下:
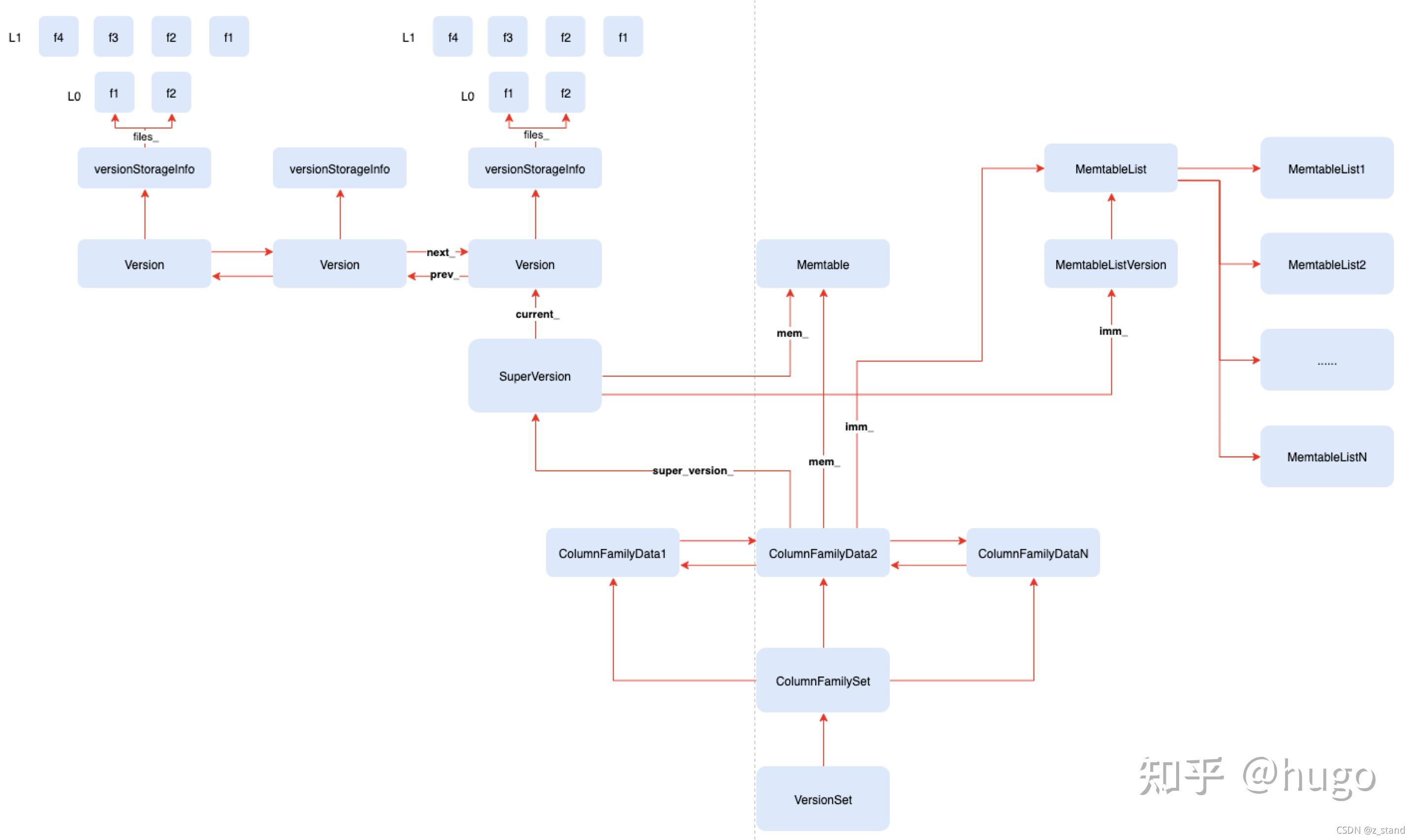
当我们 Get 或者 Seek 的时候,针对都会从当前 cf 先拿到一个 SuperVersion,通过这个 sv 来访问对应的 mem/imm/version。访问 version 的时候会直接拿当前的 current 取其versionStorageInfo,current 会指向双向链表维护的最新的 version,再去拿到对应的 sst 文件元信息去索引对应的文件(FileMeta)。
像我们的Rocksdb::GetImpl接口,不论是去读 memtable 或者 immutable 或者 sst 的都会先拿到 sv,再去具体读对应的 value:
Status DBImpl::GetImpl(const ReadOptions& read_options,
ColumnFamilyHandle* column_family, const Slice& key,
PinnableSlice* pinnable_val, bool* value_found,
ReadCallback* callback, bool* is_blob_index) {
...
// 获取当前的superversion
SuperVersion* sv = GetAndRefSuperVersion(cfd);
...
// 读memtable
if (sv->mem->Get(lkey, pinnable_val->GetSelf(), &s, &merge_context,
&max_covering_tombstone_seq, read_options, callback,
is_blob_index)) {
...
}
// 读immutable
sv->imm->Get(lkey, pinnable_val->GetSelf(), &s, &merge_context,
&max_covering_tombstone_seq, read_options, callback,
is_blob_index)) {
...
}
// 读sst
sv->current->Get(read_options, lkey, pinnable_val, &s, &merge_context,
&max_covering_tombstone_seq, value_found, nullptr, nullptr,
callback, is_blob_index);
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
如果从三个组件的任何一个能够读到,则会返回结果,并释放当前的 sv。
那接下来我们思考一下,针对 Rocksdb 的访问一定是并发的,比如并发Get ,而 memtable/sst 都是时刻在变动的(不断得 Put 产生的 flush 和 compaction),那我们的一次 Get 想要保证读到最新的数据,一定会拿到最新的 version,如果没有太多的考虑, 针对 version 的访问需要锁的保护,防止读到更新的中间状态。在这种情况下,一旦有锁的参与,我们的性能将会巨差无比。
Rocksdb 为了提升高并发场景下针对 LSM-tree 各个组件的访问性能,减少锁的参与,引入了线程私有存储。
# 1.4.2 C++ thread_local vs ThreadLocalPtr
线程私有存储 就是让每一个线程都访问自己的存储内容,当然 C++ 本身也提供了线程私有存储的关键字(thread_local),当然 rocksdb 并没有选用,而是实现了一个更为复杂的ThreadLocalPtr。
先来看一下 Rocksdb 没有选用这个关键字的原因,如下thread_local的代码:
#include <iostream>
#include <thread>
#include <unistd.h>
class A {
public:
A() {}
~A() {}
void test(const std::string &name) {
thread_local int count = 0;
++count;
std::cout << name << ": " << count << std::endl;
}
};
void func(const std::string &name) {
A a1;
a1.test(name);
a1.test(name);
A a2;
a2.test(name);
a2.test(name);
}
int main(int argc, char* argv[]) {
std::thread t1(func, "t1");
t1.join();
std::thread t2(func, "t2");
t2.join();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
我们声明了类 A的成员函数test的访问时线程私有存储方式,然后在func 中生成了两个对象, 按照我们正常的执行逻辑,两个对象的 test 函数的执行是各自输出各自的,也就是都输出 1;两个线程之间的执行互不影响。
而最终的输出结果:
t1: 1
t1: 2
t1: 3
t1: 4
t2: 1
t2: 2
t2: 3
t2: 4
2
3
4
5
6
7
8
很明显的一个问题,thread_local声明了count之后,在当前线程的所有 A 对象会共享同一个变量,我们想要一个线程内部的同一个类不通对象之间不共享,则无法生效。
其次,thread_local 无法区分不同的线程,上面的输出其实是通过外部标识了不同的线程,对于执行函数func来说,它完全无法区分当前执行的是哪一个线程。
因为这一些语言 (thread_local)/ 编译器(__thread) 本身的限制,Rocksdb 想要针对重要的 version 系统实现无锁化,就自己设计了ThreadLocalPtr。
# 1.4.3 ThreadLocalPtr 设计
设计的初衷主要是线程私有存储的灵活性:
- 在同一个线程内部区分不同对象 (可能会有多个 sv 实例)。
- 在同一个进程内部区分不同的线程 (可能不同线程同时读写一个 sv)。
- 希望在一个线程内部能够清空或者重置所有线程的 tls
- 希望运行时再确定 tls 的类型,而
thread_local和__thread都无法做到。
Rocksdb 的 ThreadLocalPtr 使用方式如下,非常简单(当然, 接口不止如下几个):
// Define a variable
ThreadLocalPtr tls;
// Write data
// thread1
tls.Reset(reinterpret_cast<int*>(1))
// tls.Swap(reinterpret_cast<int*>(1)) // 和上面的效果是一样的
// thread2
tls.Reset(reinterpret_cast<int*>(2))
// Get data
// thread1
tls.Get() == reinterpret_cast<int*>(1)
// thread2
tls.Get() == reinterpret_cast<int*>(2)
// set all thread’s tls to null
tls.Scrape(&ptrs, nullptr);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
整个ThreadLocalPtr的 类以及其相关类如下(不是标准的 UML 类图),大体能够看到其中各个成员之间的关系。
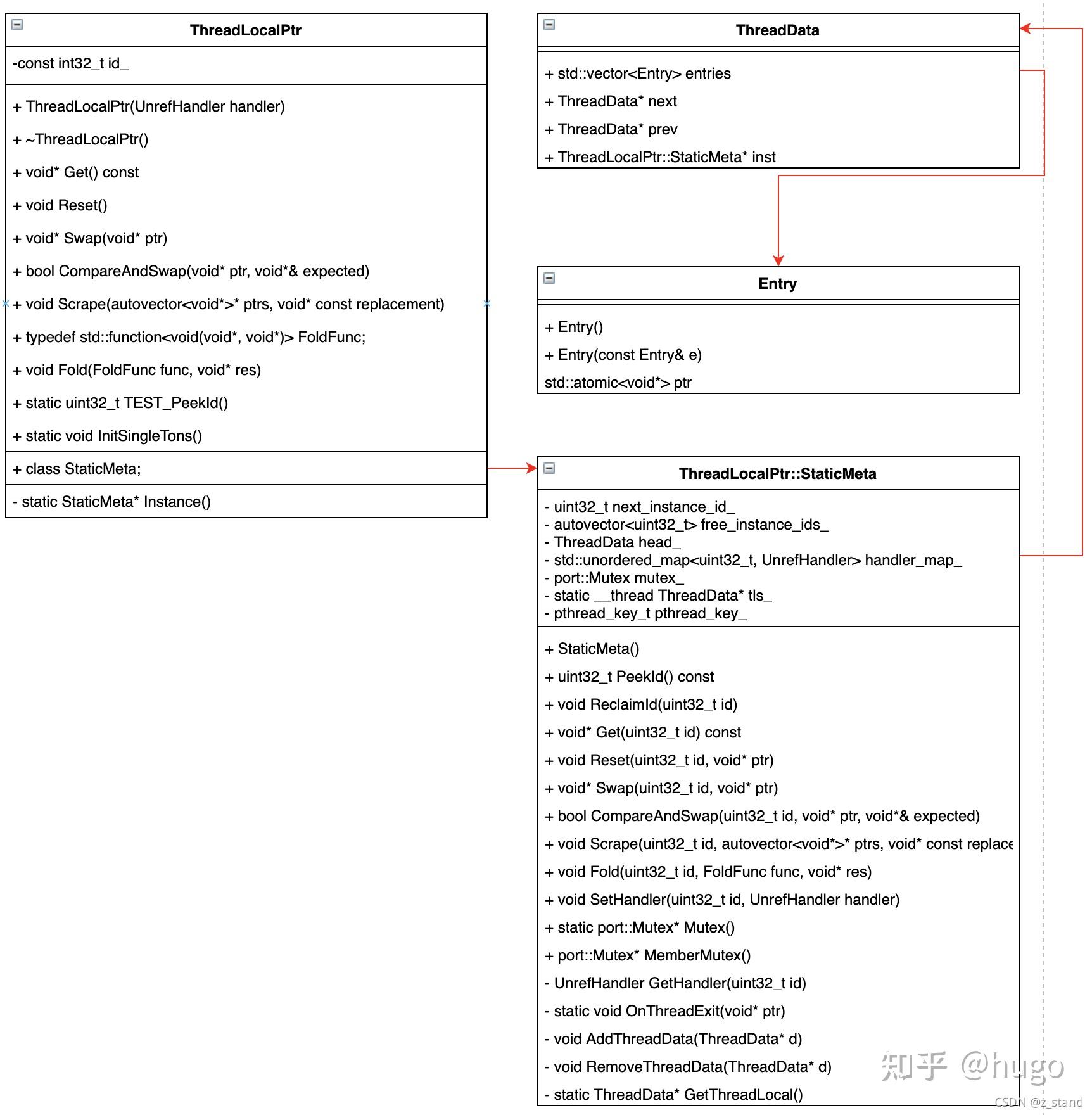
可以看到ThreadLocalPtr 除了对外的成员函数接口之外主要是一个 id_ 以及 StaticMeta::Instance()私有成员。
而StaticMeta 类中的主要成员 除了实现线程私有存储的 posix 类型pthread_key_t之外 还有一个__thread的ThreadData类型的私有成员tls_。
可以发现,我们实际的私有存储数据是存放在ThreadData 之中的Entry之中,对于私有存储数据的管理是通过ThreadData维护的双向链表进行的。而且每一个ThreadData对象都会有一个共享的ThreadLocalPtr::StaticMeta对象。
而最外部的ThreadLocalPtr的id_则能够标识访问当前私有存储的线程。
接下来我们看一下创建一个 ThreadLocalPtr 对象,不同类之间的关系形态:
- 创建第一个
ThreadLocalPtr对象local_1
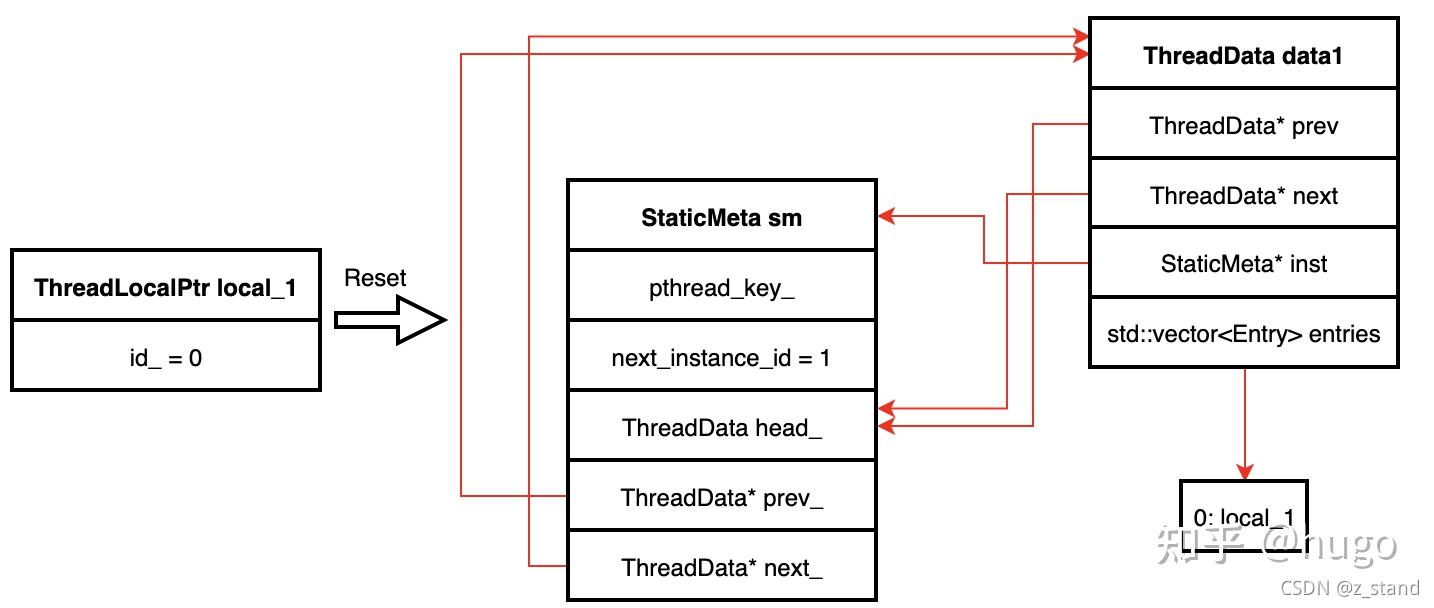
通过Reset接口,将创建好的ThreadData 采用链表的尾插法,插入到StaticMeta维护的 ThreaData 类型的head_之后,形成一个双向循环链表,同时将 Reset 传入的void* 类型的数据存储到Entry数组之中;标识下一个 ThreadLocalPtr 对象的 id 是 1。
- 创建第二个
ThreadLocalPtr对象local_2
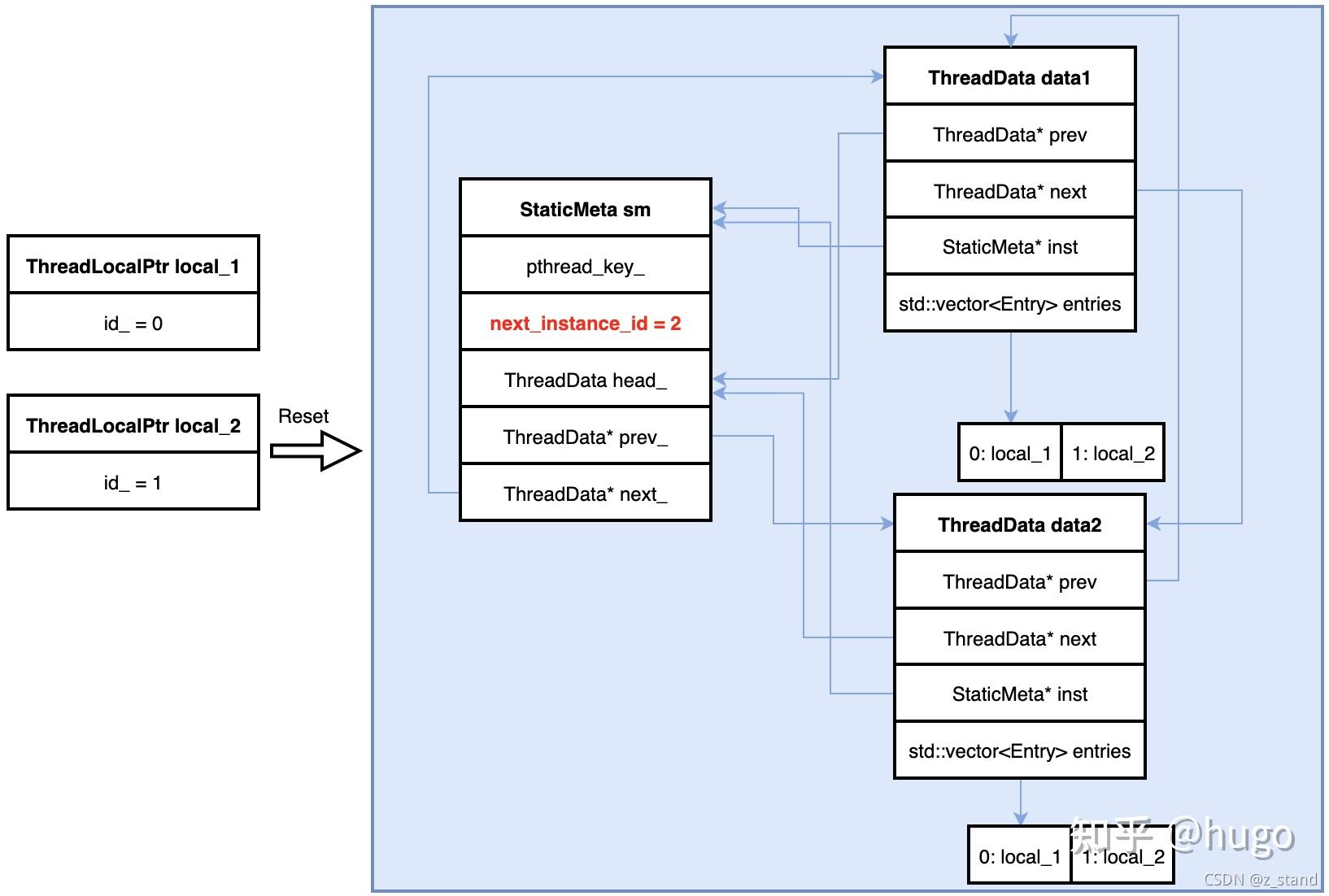
创建的第二个私有存储变量local_2 同样会创建一个ThreadData对象,采用双向链表的尾插法插入到StaticMeta维护的 双向循环链表中,并标识下一个ThreadLocalPtr 实例的 id 是 2。
这样,我们有了一个全局的StaticMeta对象(对 StaticMeta 对象的创建是单例模式),通过它的双向循环链表head_ 能够访问到所有的创建的私有存储对象。每一个双向链表的节点ThreadData都保存了所有ThreadLocalPtr对象,访问具体的哪一个线程创建的 ThreadLocalPtr 对象则通过 ThreadLocalPtr的id_标识。
具体的访问以及创建 ThreadLocalPtr 对象的代码如下:
- 访问
ThreadLocalPtr对象的代码Get:
c void* ThreadLocalPtr::StaticMeta::Get(uint32_t id) const { // 拿到全局StaticMeta 实例 的tls auto* tls = GetThreadLocal(); if (UNLIKELY(id >= tls->entries.size())) { return nullptr; } // 访问当前 线程的ThreadLocalPtr 的存储内容 return tls->entries[id].ptr.load(std::memory_order_acquire); }
- 创建
ThreadLocalPtr对象的代码Reset(存储的时候是松散内存序,可能不会立即同步到内存,仅仅同步到 cpu-cache 就返回了) /Swap(严格内存序,会从 cpu-cache 同步到内存)
```c void ThreadLocalPtr::StaticMeta::Reset(uint32_t id, void ptr) { // 拿到全局 StaticMeta 实例的 tls auto tls = GetThreadLocal(); if (UNLIKELY(id>= tls->entries.size())) { // Need mutex to protect entries access within ReclaimId MutexLock l(Mutex()); tls->entries.resize(id + 1); } // 松散内存序存储 tls->entries[id].ptr.store(ptr, std::memory_order_release); }
void ThreadLocalPtr::StaticMeta::Swap(uint32_t id, void ptr) {auto* tls = GetThreadLocal(); if (UNLIKELY(id >= tls->entries.size())) { // Need mutex to protect entries access within ReclaimId MutexLock l(Mutex()); tls->entries.resize(id + 1); } // 严格内存序列内存 CAS return tls->entries[id].ptr.exchange(ptr, std::memory_order_acquire); } ```
# 1.4.4 ThreadLocalPtr 在 version 系统中的应用
回到我们最初 version 系统中的SuperVersion,读取操作主要是依赖 superversion。Rocksdb 这里针对 SuperVersion 的操作主要提供了如下两个函数:
InstallSuperVersion // 后台线程flush/compaction 完成之后会更新 全局的superversion 以及 清理所有的 tls superversion
GetReferencedSuperVersion // 获取 local tls 的sv,如果过期了,则会重新从全局的sv中获取一个新的sv进行访问;否则直接拿到local 的 sv进行访问。
2
通过如下图能够非常清晰得看到 tls(thread local storage) 在 version 系统的重要作用。
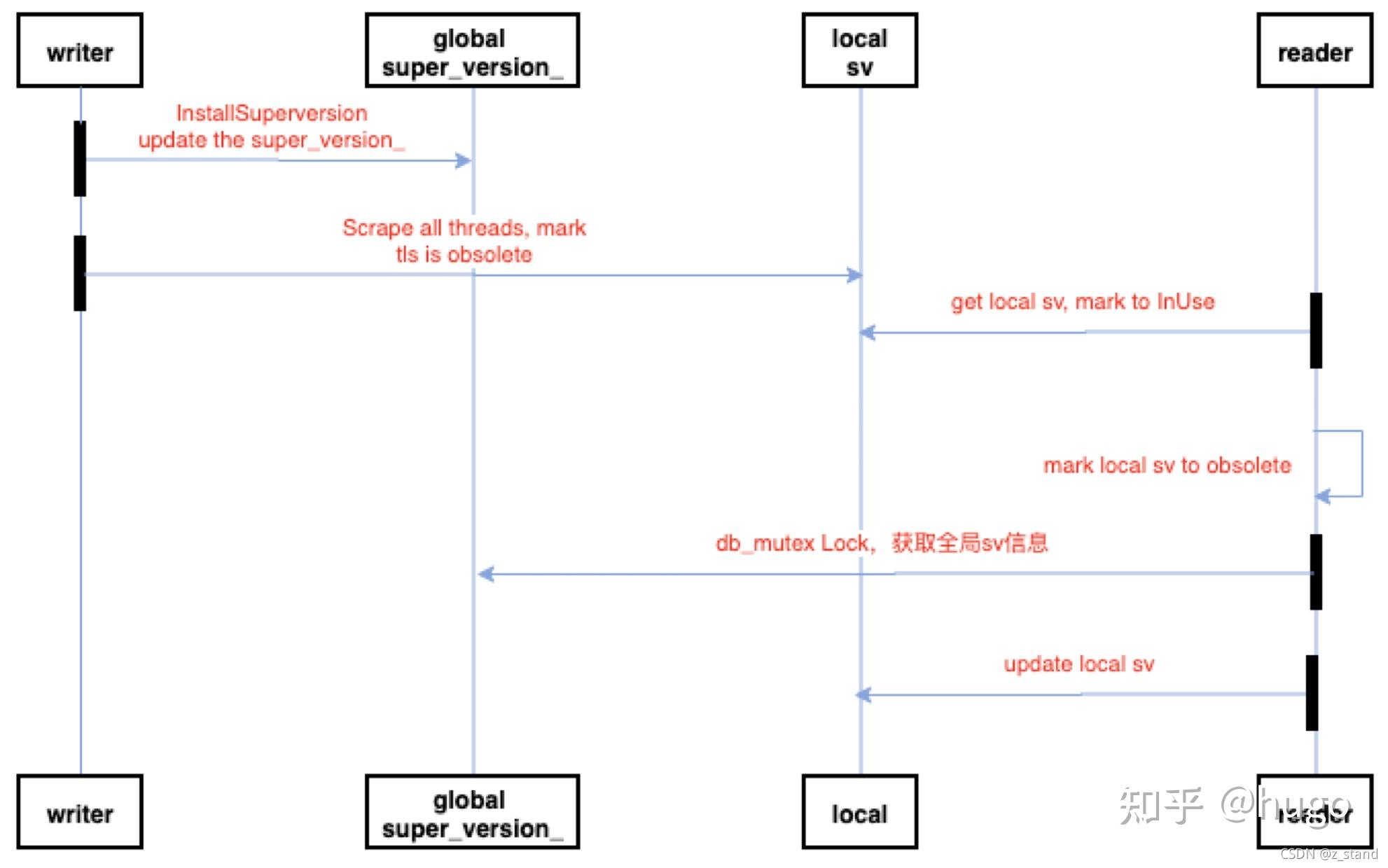
我们的writer 和 reader 可以看作是用户调用的Put 和 Get 操作,每一个操作代表一个并发线程。
Writer 操作会引入 flush 以及 compaction 操作,BackGroundCompaction --> InstallSuperVersionAndScheduleWork --> InstallSuperVerion 的时候会先更新全局的super_version_,同时将所有的 tls sv 通过ResetThreadLocalSuperVersions设置为 obsolute。
代码如下:
void ColumnFamilyData::ResetThreadLocalSuperVersions() {
autovector<void*> sv_ptrs;
// 对tls 的所有 ThreadLocalPtr 对象进行通知标记(读请求拿到的tls也能够感知到)
local_sv_->Scrape(&sv_ptrs, SuperVersion::kSVObsolete);
for (auto ptr : sv_ptrs) {
assert(ptr);
if (ptr == SuperVersion::kSVInUse) {
continue;
}
auto sv = static_cast<SuperVersion*>(ptr);
bool was_last_ref __attribute__((__unused__));
was_last_ref = sv->Unref();
// sv couldn't have been the last reference because
// ResetThreadLocalSuperVersions() is called before
// unref'ing super_version_.
assert(!was_last_ref);
}
}
// Scrape 的操作就是通过 StaticMeta 单例对象来遍历循环链表中的 tls存储,逐个标记
void ThreadLocalPtr::StaticMeta::Scrape(uint32_t id, autovector<void*>* ptrs,
void* const replacement) {
MutexLock l(Mutex());
for (ThreadData* t = head_.next; t != &head_; t = t->next) {
if (id < t->entries.size()) {
void* ptr =
t->entries[id].ptr.exchange(replacement, std::memory_order_acquire);
if (ptr != nullptr) {
ptrs->push_back(ptr);
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
这个时候,Writer 通过Scrape 标记了当前 db 的所有的 tls 存储为过期,完成标记之前 可能有一个 reader 通过 GetReferencedSuperVersion 创建了一个 tls 对象,创建完成之后被Scrape 标记了过期,那这个时候 reader 需要通过 db 级别的锁来获取全局最新的super_version_,获取之后再更新本地的 local_sv。
需要注意的是获取全局 super_version_ 的时候需要保证获取期间不会有其他的 writer 更新这个 super_version_。
代码如下:
SuperVersion* ColumnFamilyData::GetThreadLocalSuperVersion(
InstrumentedMutex* db_mutex) {
// The SuperVersion is cached in thread local storage to avoid acquiring
// mutex when SuperVersion does not change since the last use. When a new
// SuperVersion is installed, the compaction or flush thread cleans up
// cached SuperVersion in all existing thread local storage. To avoid
// acquiring mutex for this operation, we use atomic Swap() on the thread
// local pointer to guarantee exclusive access. If the thread local pointer
// is being used while a new SuperVersion is installed, the cached
// SuperVersion can become stale. In that case, the background thread would
// have swapped in kSVObsolete. We re-check the value at when returning
// SuperVersion back to thread local, with an atomic compare and swap.
// The superversion will need to be released if detected to be stale.
// 标记当前创建的 tls 是 kSVInUse,
void* ptr = local_sv_->Swap(SuperVersion::kSVInUse);
// Invariant:
// (1) Scrape (always) installs kSVObsolete in ThreadLocal storage
// (2) the Swap above (always) installs kSVInUse, ThreadLocal storage
// should only keep kSVInUse before ReturnThreadLocalSuperVersion call
// (if no Scrape happens).
assert(ptr != SuperVersion::kSVInUse);
SuperVersion* sv = static_cast<SuperVersion*>(ptr);
// 检测标记之后 可能因为writer 的 install 导致的Obsolete,则需要重新获取全局的sv
if (sv == SuperVersion::kSVObsolete ||
sv->version_number != super_version_number_.load()) {
RecordTick(ioptions_.statistics, NUMBER_SUPERVERSION_ACQUIRES);
SuperVersion* sv_to_delete = nullptr;
if (sv && sv->Unref()) {
RecordTick(ioptions_.statistics, NUMBER_SUPERVERSION_CLEANUPS);
db_mutex->Lock();
// NOTE: underlying resources held by superversion (sst files) might
// not be released until the next background job.
// 因为当前拿到的sv 已经过期了, 需要清理掉它占用的资源
sv->Cleanup();
sv_to_delete = sv;
} else {
db_mutex->Lock();
}
// 加锁获取全局的 super_version_
sv = super_version_->Ref();
db_mutex->Unlock();
delete sv_to_delete;
}// 当然,如果拿到的tls sv 并没有被标记为过期,则直接返回访问即可。
assert(sv != nullptr);
return sv;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
writer 更新 全局 super_version_ 并 标记所有的 tls sv 失效,reader 拿到 tls sv 做一些 检测 发现失效则通过 db 锁进行同步。
这个过程对 version 系统的访问能够极大得减少多线程下对 version 系统访问的同步开销,提升了 rocksdb 的读写性能。
# 2. 写链路
# 2.1 JoinBatchGroup
从 JoinBatchGroup 代码细节 来看 Rocskdb 对写入逻辑的性能优化 (opens new window)
# 3. 其他
# 3.1 用最低的代价获取 critical path 的 Statistics
Rocksdb 拥有非常完善的运维体系,包括一百多个 tickers 和 几十个 histograms。这一些指标都是嵌入到整个 rocksdb workload 的 critical path 之中。比如DB_GET 表示 Get 请求的延时,也就是每一次调用 Get 都会记录一次延时,并且后续通过rocksdb.db.get.micros 取的时候计算直方图信息。
那如何保证在打开 statistics 之后 这么多关键路径的指标不会影响引擎本身的性能,且指标的存放和读取不会耗费过多的 cpu 呢?
引擎指标对于上层应用来说是必不可少的,那如何保证指标这里的性能就成为的关键了,接下来我们学习一下 Rocksdb 这里是怎么做的。
- 指标的收集
以 histogram 类型的指标为例,DB_GET。在GetImpl入口处 通过StopWatch sw(env_, stats_, DB_GET);进行收集。 即 StopWatch类的构造函数是打一个时间点,析构函数会做一个时间差通过reportTimeToHistogram记录到 statistics 中。
~StopWatch() {
if (elapsed_) {
if (overwrite_) {
*elapsed_ = env_->NowMicros() - start_time_;
} else {
*elapsed_ += env_->NowMicros() - start_time_;
}
}
if (elapsed_ && delay_enabled_) {
*elapsed_ -= total_delay_;
}
if (stats_enabled_) {
statistics_->reportTimeToHistogram(
hist_type_, (elapsed_ != nullptr)
? *elapsed_
: (env_->NowMicros() - start_time_));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 指标的存储 存储 histogram 数据的调用栈如下:
reportTimeToHistogram
Statistics::recordInHistogram
StatisticsImpl::recordInHistogram
2
3
在recordInHistogram函数中,实现逻辑如下:
void StatisticsImpl<TICKER_MAX, HISTOGRAM_MAX>::recordInHistogram(
uint32_t histogramType, uint64_t value) {
assert(histogramType < HISTOGRAM_MAX);
if (get_stats_level() <= StatsLevel::kExceptHistogramOrTimers) {
return;
}
per_core_stats_.Access()->histograms_[histogramType].Add(value);
if (stats_ && histogramType < HISTOGRAM_MAX) {
stats_->recordInHistogram(histogramType, value);
}
}
2
3
4
5
6
7
8
9
10
11
可以发现真正的存储是存放在了per_core_stats_.Access()->histograms_[histogramType].Add(value),也就是一个StatisticsData类型的CoreLocalArray中。
StatisticsData 的定义中重载了new和delete 操作符,保证分配和释放都是cacheline对齐的。
为什么要有一个CoreLocalArray呢?
先来看看它的作用,通过Access函数 我们进入到了AccessElementAndIndex中
template <typename T>
std::pair<T*, size_t> CoreLocalArray<T>::AccessElementAndIndex() const {
// 获取当前的cpu-id
int cpuid = port::PhysicalCoreID();
size_t core_idx;
if (UNLIKELY(cpuid < 0)) {
// cpu id unavailable, just pick randomly
// 如果cpu id不可用,直接随便选择一个cpu id
core_idx = Random::GetTLSInstance()->Uniform(1 << size_shift_);
} else {
// 否则选择当前的cpu id
core_idx = static_cast<size_t>(cpuid & ((1 << size_shift_) - 1));
}
// 取当前cpu-id 缓存的 StatisticsData 类型的地址返回。
return {AccessAtCore(core_idx), core_idx};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
最后使用当前 cpu id 的 对象地址 Add 记录下来的指标数据。
大体上能够发现,我们的指标数据是缓存在执行当前Get操作的 cpu 上。
后续拿该指标的时候通过getHistogramImplLocked
std::unique_ptr<HistogramImpl>
StatisticsImpl<TICKER_MAX, HISTOGRAM_MAX>::getHistogramImplLocked(
uint32_t histogramType) const {
assert(histogramType < HISTOGRAM_MAX);
std::unique_ptr<HistogramImpl> res_hist(new HistogramImpl());
// 访问当前cpu的所有core,取每一个core 之前存储的该指标的数据。
for (size_t core_idx = 0; core_idx < per_core_stats_.Size(); ++core_idx) {
res_hist->Merge(
per_core_stats_.AccessAtCore(core_idx)->histograms_[histogramType]);
}
return res_hist;
}
2
3
4
5
6
7
8
9
10
11
12
我们大概知道了CoreLocalArray在指标集中的用法, 那 rocksdb 为什么要用这样的方式保存指标呢?
在关键路径上的额外处理逻辑每一步都可能影响性能,我们将指标随便保存在内存中,后续的用户线程 以及 引擎内部的 stats 打印线程 读取则可能涉及跨 numa 访问,同样会造成额外的 cpu 开销。
如果我们将指标按照 core-id 保存在各自 core 的本地存储中(cpu-cache / 距离 cpu 近的内存中),而且保证了StatisticsData的分配和释放都是 cache-line 对齐,那么在访问过程中从本地 core 存储按照 cache-line 读取能够极大得减少跨 numa 以及 cache-line 补齐 的开销,最大程度得保证了指标访问的性能 ,减少对系统 CPU 资源的占用。
全文完
本文由 简悦 SimpRead (opens new window) 优化,用以提升阅读体验
使用了 全新的简悦词法分析引擎 beta,点击查看 (opens new window)详细说明
1. 读链路 (opens new window)1.1 FileIndexer (opens new window)1.1.1 LevelDB sst 查找实现 (opens new window)1.1.2 Rocksdb FileIndexer 实现 (opens new window)1.2 PinnableSlice 减少内存拷贝 (opens new window)1.3 Cache (opens new window)1.3.1 LRU Cache (opens new window)1.3.2 Clock Cache (opens new window)1.4 ThreadLocalPtr 线程私有存储 (opens new window)1.4.1 version 系统 (opens new window)1.4.2 C++ thread_local vs ThreadLocalPtr (opens new window)1.4.3 ThreadLocalPtr 设计 (opens new window)1.4.4 ThreadLocalPtr 在 version 系统中的应用 (opens new window)2. 写链路 (opens new window)2.1 JoinBatchGroup (opens new window)3. 其他 (opens new window)3.1 用最低的代价获取 critical path 的 Statistics (opens new window)