# 本文主要是介绍 VLDB 2021 中一些与 PM,AI+Data,分布式数据库,内存数据库,以及云存储和大数据相关(在下一版本中添加)的论文,其中一部分介绍是论文的摘要
# Taurus: Lightweight Parallel Logging for In-Memory Database Management Systems
DBMS 通过写入一个持久性的 WAL 来实现故障恢复,这样的单一串行日志可能成为 in-memory 数据库的性能瓶颈。本文使用向量化的日志追踪事务之间的依赖关系,可以并行写入和回放日志。为了减少时间戳占用的空间,本文提出了时间戳压缩算法。可以与 S2PL,OCC,MVCC 等并发控制结合。
# Scaling Replicated State Machines with Compartmentalization
本文使用一系列的解耦操作提升 MultiPaxos 共识协议的可扩展性。
\1. Proxy Leader,解耦指令排序和广播,避免 Leader 成为瓶颈
\2. Acceptor Grid,解耦读写仲裁
\3. More Replicas,由于添加了 Proxy Leader,增加更多的副本不会导致 Leader 成为瓶颈,同时每个副本负责的响应数量减少。
\4. Leaderless Read:解耦读写路径。写入像以前一样处理,但绕过领导者并使用 Paxos Quorum Reads (PQR) 在单个副本上执行读取。 具体来说,为了执行读取,客户端发送 PreRead⟨⟩ 消息到接收者的读取仲裁。 然后它向任何一个副本发送 Read⟨x,i⟩ 请求,当副本接收到来自客户端的 Read⟨x,i⟩ 请求时,它会等待直到它执行了日志条目 i 中的命令。
\5. Batchers:批处理通过分摊处理命令的通信和计算成本来提高吞吐量,通过引入 Batchers 解耦指令排序和批处理。
\6. UnBatchers:在执行了 n 条命令后,副本(Replica)必须向 n 个客户端发送 n 条消息。因此,副本 (就像没有批处理程序的 leader) 所遭受的通信开销在命令数量上是线性的,而不是在批处理数量上。通过引入一组至少 f + 1 的反批处理程序来解除这两个职责的耦合,副本负责执行批量命令,而反批处理程序负责将执行命令的结果发送回客户机。
# FlexPushdownDB: Hybrid Pushdown and Caching in a Cloud DBMS
现代云数据库采用了存储分解架构,将计算和存储的管理分开。这种架构的一个主要瓶颈是连接计算层和存储层的网络。两种解决方案已被探索以缓解瓶颈: 缓存(将数据缓存在计算层)和计算下推(将过滤和组合操作在靠近存储的地方执行)。虽然这两种技术都可以显著减少网络流量,但现有的 dbms 只支持其中一种,从而限制了潜在的性能优势。
FlexPushdownDB: 构建了一个混合查询执行器,将缓存中的数据和下推处理的结果结合。还提出了一种新的加权 LFU 缓存替换策略,考虑了下推计算的成本。总体架构如下图所示。
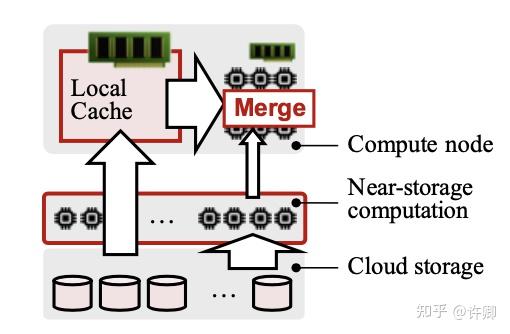
混合查询执行器:查询执行器从优化器接收逻辑查询计划,并根据缓存中的内容将其转换为可分离的查询计划。可分离查询计划处理计算节点中的缓存数据,并将未缓存数据的过滤器和聚合推到存储层。然后,这两部分被合并并输送给下游运营商。第 4 节将讨论操作符如何分离和合并的细节。
缓存管理器:缓存管理器决定哪些数据应该缓存到计算节点中。缓存回收策略考虑了计算下推的存在,以进一步提高性能。对于每个查询,缓存管理器更新被访问数据的元数据 (例如,访问频率),并决定是否应该发生接纳和 / 或驱逐。每次访问缓存时,计数器都增加一个权重,权重的值取决于段是否可以下推,如果可以,下推的代价是多少。直观地说,下推的代价越高,我们从缓存中得到的好处就越多,因此权重也就越高。
# Epoch-based Commit and Replication in Distributed OLTP Databases
本文介绍了分布式 OLTP 数据库 COCO,支持基于事务 epoch 的提交和异步复制,支持使用物理时间和逻辑时间以及各种优化的乐观并发控制 (OCC)
在 COCO 中,在一个纪元中运行和提交一批事务。但是,每个事务的结果直到 epoch 结束时才返回,此时所有参与节点都同意提交当前 epoch 中的所有事务,系统需要确保主副本与所有备份副本在 epoch 边界上保持一致,系统每隔几毫秒 (例如,默认是 10 毫秒) 增加全局 epoch。
COCO 中的事务运行在两个阶段: 执行阶段和提交阶段。发起事务的节点是协调节点,其他节点是参与节点。
- 在准备阶段,协调器向每个参与节点发送准备消息。
- 在提交阶段,协调器首先决定当前 epoch 是否可以提交。如果任何参与节点由于失败而不能响应确认,则当前时代的所有事务将终止。
COCO 非常适合大多数事务都是短期的工作负载。实际上,大多数长时间运行的事务都是只读的分析事务,可以将其配置为在稍微陈旧的数据库快照上运行。长时间的写事务会降低系统的吞吐量。
# Understanding the Idiosyncrasies of Real Persistent Memory
高容量持久内存 (PMEM) 最终以英特尔的 Optane DC 持久内存模块 (DCPMM) 的形式上市。对 DCPMM 的早期评估表明,它的行为比之前认为的更加微妙和特殊。然而,DCPMM 的几个特殊性能特征与所使用的存储技术 (3D-XPoint) 及其内部结构有关。
本文通过在真实的 DCPMM 中测试,分类了 PMEM 的特殊行为,包括顺序和随机读写性能,小型随机 IO 的带宽以及 load/p-store 的延迟,并总结分析了一般 PMEM 的特性,在此基础上,本文的第一项研究指导使用 PMEM 的 NUMA 系统的数据放置,第二项研究指导使用 eADR 和 ADR 的 PMEM 系统的无锁数据结构的设计。
# Viper: An Efficient Hybrid PMem-DRAM Key-Value Store
基于 PMEM 和 DRAM 混合的 KV-Store,本文认为直接用 PMem 替换现有存储并不会产生好的结果,因为基于块的访问在 PMem 中与在磁盘上的行为不同,并且忽略了 PMem 的字节可寻址性、布局和独特的性能特征。Viper 采用基于 DRAM 的哈希索引和 PMem 感知的存储布局,利用 DRAM 的随机写速度和高效的顺序写性能 PMem。
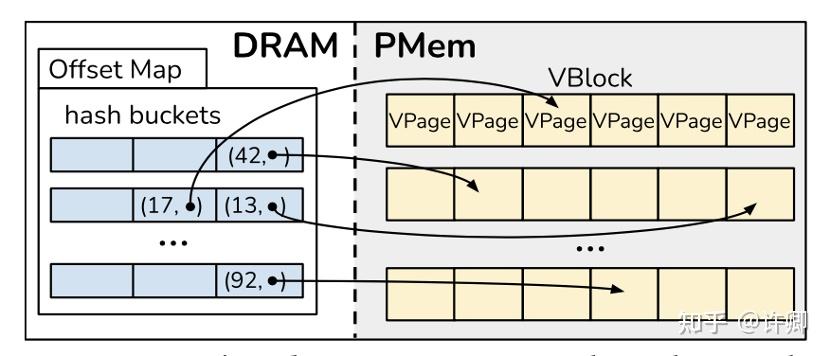
Viper 由三个主要组件组成,持久的 VBlocks 和 VPages,以及内存中的 Offset Map。Viper 的 volatile Offset Map,通过存储每个记录的键和持久存储位置充当索引。
在 Viper 中,将 Vblock 与底层交错的 dimm 集的边界对齐,正好跨越 24 KB。每个 VBlock 包含固定数量的 VPage,每个 DIMM 对应一个 VPage,存储在本地阵列中,以便高效访问。Vblock 本身不包含逻辑,只是作为 VPages 的分组来减少 Viper 中的记录开销。每个 VPage 是 4kb(内存对齐),包含一些元数据和存储在槽中的实际键值记录。为了支持更大的键值对,Viper 可以将 VPages 扩展为 4 KB 的倍数,将 VBlocks 扩展为 24 KB 的倍数,确保相同的 4 KB 和 24 KB 对齐。
在更新数据时,如果数据不能就地修改(通过原子指令),Viper 就插入新的数据。
# Revisiting the Design of LSM-tree Based OLTP Storage Engine with Persistent Memory
本文研究了如何利用 PM 重新设计的基于 lsm 树的 OLTP 存储期引擎。
- 提出了一个名为 Halloc 的轻量级 PM 分配器,该分配器为 LSM-tree 定制,(2) 构建一个高性能的半持久 Memtable,利用 PM 的持久内存写入
- 设计一个名为 Reorder Ring 的并发提交算法,以实现 OLTP 工作负载的无日志事务处理;
- 提出一个全局索引作为新的全局排序持久层,并进行无阻塞的内存压缩
Reorder Ring 和 Semi-persistent Memtable 的设计实现了快速的写入,而不需要同步日志开销,并实现了接近即时的恢复时间。此外,具有内存压缩的半持久 Memtable 和全局索引的设计使 PM 中的字节可寻址持久级别能够显著减少读写放大以及后台压缩开销。
# Zen: a High-Throughput Log-Free OLTP Engine for Non-Volatile Main Memory
本文是将 DRAM 与 NVM 结合的 OLTP 存储引擎,Zen 的优化主要包括元数据增强的元组缓存(Met-Cache),无日志的持久事务和轻量级 NVM 空间管理。
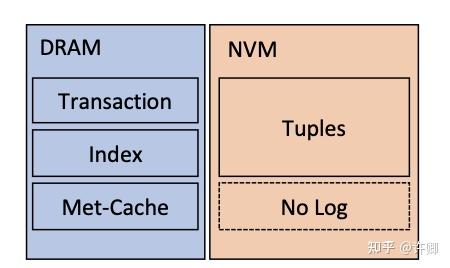
- Met-Cache: 在 DRAM 中 (i) 缓存当前正在运行的事务中使用的或最近使用过的元组,以及 (ii) 用每个元组所需的元数据来扩充每个元组并发控制方法。通过这种方式,Zen 主要在 DRAM 中执行并发控制,避免将 per-tuple 元数据写入 NVM 中进行元组读取,并减少频繁访问的元组的 NVM 读取。
- Log-Free:使用多版本,异地更新
- 轻量级 NVM 空间管理:通过两级 NVM 空间管理尽可能减少 NVM 空间管理的持久性操作。从底层系统分配大(2MB 大小)的 NVM 内存块,所以在 NVM 中记录页面分配的操作并不频繁。Zen 可以在恢复时识别最近提交的元组版本,然后将旧的元组版本放入空闲列表中。分配结构在正常处理期间保持在 DRAM 中,Zen 垃圾收集旧的元组版本并将它们放入空闲列表中以进行元组分配,每个线程都有自己的分配结构,以避免线程同步开销。
# Optimizing In-memory Database Engine For AI-powered On-line Decision Augmentation Using Persistent Memory
这是我比较喜欢的一篇论文,考虑了 AI 计算场景的特性,同时又使用 PM 对系统进行优化,综合考虑了系统性能与成本,有关本文的内容可以参考第四范式的中文介绍
4PD 开发者社区:第四范式 OpenMLDB 优化创新论文被国际数据库顶会 VLDB 录用 (opens new window)
# Updatable Learned Index with Precise Positions
如果对 Learned Index 不熟悉可以先参考中科大的中文综述文章:
学习索引: 现状与研究展望 (opens new window)
本文提出了 LIPP,一个全新的学习索引框架来解决这些问题。与最先进的学习索引结构类似,LIPP 能够支持各种索引操作,即查找查询、范围查询、插入、删除、更新和批量加载。同时克服了前人研究的局限性,在处理更新操作时适当扩展了树的结构,从而消除了模型在叶节点中预测的位置偏差。此外,本文还提出了动态调整策略确保索引 Tree 的有限高度。
# Persistent Memory Hash Indexes: An Experimental Evaluation
本文使用真正的 PM 硬件对持久哈希表进行了全面的评估。我们特别关注 6 个最先进的哈希表的评估,包括 Level Hash、CCEH、Dash、PCLHT、Clevel 和 SOFT。除了描述常见的性能属性外,还探讨硬件配置 (如 PM 带宽、CPU 指令和 NUMA) 如何影响基于 PM 的哈希表的性能。通过深入的分析,确定了现有技术中的设计权衡和良好的范例,并为基于 pm 的哈希表的未来发展提出了理想的优化和方向。
- 随机小写是从根本上限制 PM 哈希表性能的主要因素。
- 缓存刷新和内存栅栏指令对性能的影响很小。
- 指纹识别可以显著地加速负查询(数据不存在)。
- Resize 不应阻碍正常操作。
- 注意由内存分配器和同步原语引起的写扩展的重要性
- 对混合内存设计的关注。在 DRAM 中维护结构化元数据,在 PM 中维护键值对,可以从根本上减少 PM 的读写和访问延迟。然而,未来应该考虑新的技术来降低混合存储器设计的恢复成本。
- PM 带宽是一种稀缺资源,但哈希表的性能不一定会随着 DCPMM 的增加而提高。
- PM 物质的微观结构特征,XPBuffer,WPQ 等。
# Constructing and Analyzing the LSM Compaction Design Space
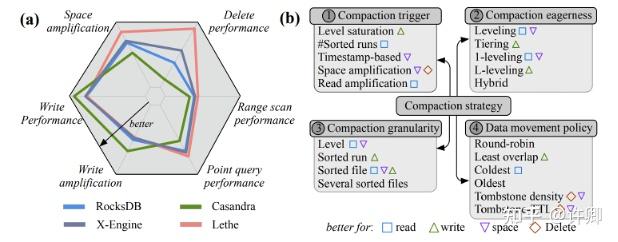
Compaction 从根本上影响 LSM 引擎的性能,包括写放大、写吞吐量、点和范围查找性能、空间放大和删除性能。因此,选择合适的 Compaction 策略是至关重要的,同时,由于 LSM-Compaction 设计空间广阔,很大程度上未被探索,而且在文献中还没有正式定义。因此,大多数基于 lsm 的引擎使用固定的压缩策略,该策略决定如何以及何时压缩数据。
在本文中提出了 LSM-Compaction 的设计空间,并根据关键性能指标评估最先进的 Compaction 策略。通过引入一组四种设计原语,它们可以正式定义任何 Compaction 策略:(i)压缩触发器,(ii)数据布局,(iii)压缩粒度,以及 (iv) 数据移动策略;另外本文通过实验分析了 10 种 Compaction 策略。
# openGauss: An Autonomous Database System
本文是介绍华为开源数据库系统 openGauss 的基于机器 / 强化学习的数据库技术。包括学习型优化器 (包括学习型查询重写、学习型成本 / 基数估计、学习型连接顺序选择和物理操作符选择) 和学习型数据库建议器(包括自监控、自诊断、自配置和自优化)。
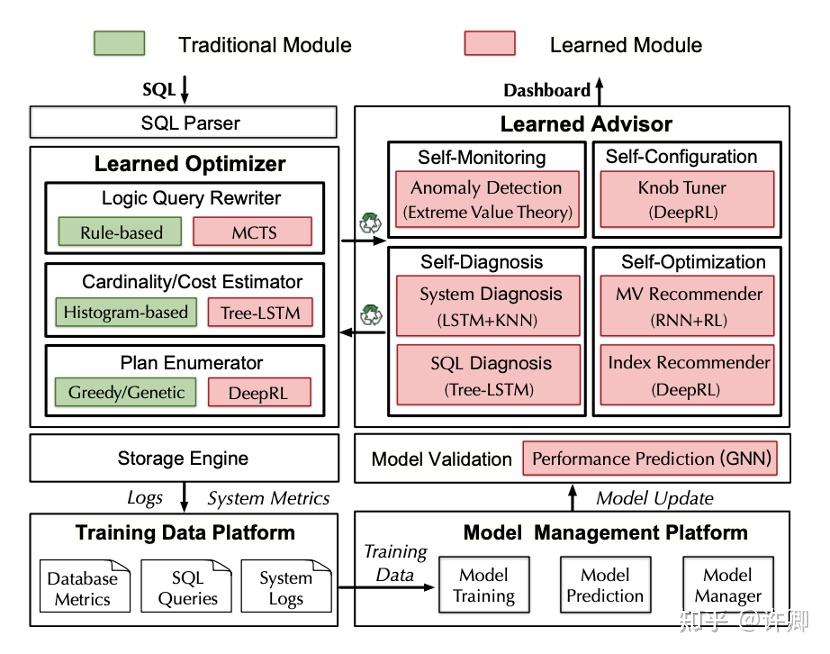
基于学习的查询重写使用基于蒙特卡罗树搜索的方法,智能地将 SQL 查询重写为一个等价的但更有效的查询。学习型成本 / 基数估计使用 tree-LSTM 同时估计成本和基数。学习型计划生成器利用深度强化学习选择良好的连接顺序和适当的物理操作。
openGauss 的学习型 Database Advisors:基于学习的自我监控、自我诊断、自我配置和自我优化技术来监控、诊断、配置和优化数据库。自我监控监视数据库指标,并使用这些指标来帮助其他组件。自诊断采用 tree-LSTM 检测异常,识别异常的根本原因。自配置使用深度强化学习方法来调整旋钮。自优化使用 encoder-reducer 模型推荐视图,使用深度强化模型推荐索引。
限于作者能力,本文中会存在一些理解错误的地方,更多详细的内容还是需要阅读原文
由于现在对大数据和云计算还不熟悉,在后面会添加这两方面相关的论文。
全文完
本文由 简悦 SimpRead (opens new window) 优化,用以提升阅读体验
使用了 全新的简悦词法分析引擎 beta,点击查看 (opens new window)详细说明
本文主要是介绍 VLDB 2021 中一些与 PM,AI+Data,分布式数据库,内存数据库,以及云存储和大数据相关(在下一版本中添加)的论文,其中一部分介绍是论文的摘要 (opens new window)Taurus: Lightweight Parallel Logging for In-Memory Database Management Systems (opens new window)Scaling Replicated State Machines with Compartmentalization (opens new window)FlexPushdownDB: Hybrid Pushdown and Caching in a Cloud DBMS (opens new window)Epoch-based Commit and Replication in Distributed OLTP Databases (opens new window)Understanding the Idiosyncrasies of Real Persistent Memory (opens new window)Viper: An Efficient Hybrid PMem-DRAM Key-Value Store (opens new window)Revisiting the Design of LSM-tree Based OLTP Storage Engine with Persistent Memory (opens new window)Zen: a High-Throughput Log-Free OLTP Engine for Non-Volatile Main Memory (opens new window)Optimizing In-memory Database Engine For AI-powered On-line Decision Augmentation Using Persistent Memory (opens new window)Updatable Learned Index with Precise Positions (opens new window)Persistent Memory Hash Indexes: An Experimental Evaluation (opens new window)Constructing and Analyzing the LSM Compaction Design Space (opens new window)openGauss: An Autonomous Database System (opens new window)