目录:
# 文章目录
- 1. 简述 (opens new window)
- 2. 分阶段讨论 (opens new window)
- 3. 推荐效果评价 (opens new window)
- 4. 冷启动 (opens new window)
- 其他特征 (opens new window)
- 神经网络进阶 (opens new window)
- 相关 FAQ (opens new window)
- 参考 (opens new window)
# 1. 简述
推荐系统用处很大, 遍地开花, 什么都可以推荐, 如抖音推荐视频, 百度推荐广告, 淘宝推荐商品, 咨询应用推荐文章 等等. 用了推荐系统, 用户点击变多了, 商家也赚得多了, 何乐不为呢? 本文就以商品推荐为例, 把各种做法和实现原理做个综述.
一般讲推荐的文章, 只提思想, 略过了工程实现, 而要工程落地的话, 就必须思考 数据结构怎么设计, 哪些数据是线下准备的, 哪些数据是线上计算的, 推荐系统各模块之间的耦合和联系又是怎样的 等问题. 笔者作为一个热心肠的人, 就把业界的惯用做法放出来, 让大家过一下瘾.
推荐的本质很简单: 给一个足够大的候选池, 挑出用户在没有明确意图下的最感兴趣的优质东西. 所以要做的事情有两块:
- 计算商品与用户兴趣的相关度.
- 用户希望看到优质热门商品, 所以要结合商品的质量分综合排序.
推荐系统大致的处理流程我画了出来:
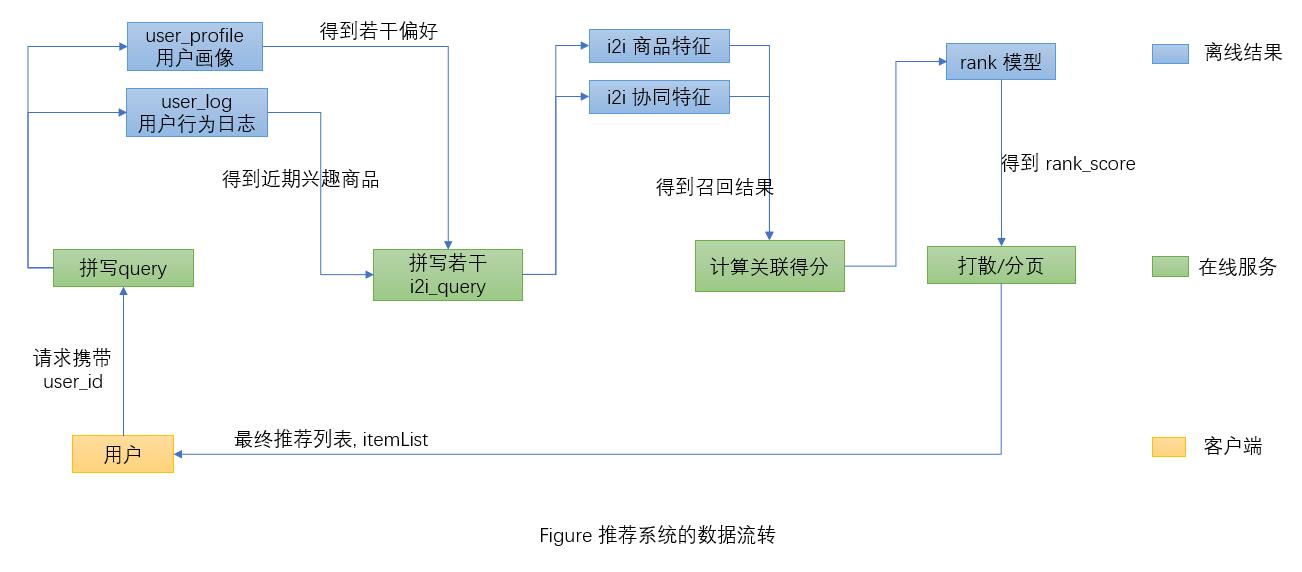
figure 1 推荐系统的数据流转
# 2. 分阶段讨论
对于图 1 的流程, 我们分阶段讨论.
# 离线数据准备
# 协同数据
基本思想:在购买了item_1物品的用户集合中,很多也买了item_2,那么其他item_1的购买者也是item_2的潜在购买者。
在此基本思想上, 还可以运用很多改进算法. 所以我们可以讲协同是一类算法的统称. 它们的输入输出是这样的:
input : < user_id, click_item_list>
output: < item_id, proximate_item_list>
更多讨论见我的另一篇文章 <<推荐系统中的 match 阶段>> , 见参考 [1].
# 特征数据
需要事先建立起衔接 用户偏好 与 商品特征的特征维度. 如 卖家, 一级类目, 叶子类目 等.
- 对用户 为了更好的区分不同的偏好维度, 可以用到 Trigger 这种数据结构.
class Trigger{
long triggerType; // 主键, 便于UserTrigger 与 ItemTrigger 通过主键当外键使用.
long triggerId; //如 偏爱类目id
double score; //此trigger的重要程度. 比如 商品协同 要比 类目匹配 优先考虑.
}
2
3
4
5
借助于 trigger 体系, 通常用数据结构UserTrigger表示用户特征.
class UserTrigger{
long userId; //用户id
Trigger trigger;
double score; // 偏爱程度, 可以用 [0,1] 正规化
}
2
3
4
5
把这些记录放在表User2ItemTrigger中的话, 联合主键为userId,triggerType,triggerId.
这里的Item 并不是商品, 而是是泛指品牌, 类目这种.
- 对商品 商品的特征包括两部分: 品牌, 类目等固有属性是后台上架时本身就有的; 适用人群等信息还是上架一段时间后基于统计得到的. 在建立商品的 i2i 召回数据时, 也可以用下面的数据结构.
class ItemTrigger{
long itemId; //商品id
Trigger trigger;
double score; // 联系紧密程度, 可以用 [0,1] 正规化
}
2
3
4
5
像购买能力这种关键特征, 存储的详细一点比较好. 比如购买能力不能只按价格区分, 因为不同的东西价格档位就不一样 (如 手机普遍千元以上, 但台灯在百元左右). 同一个用户, 在不同类目下的消费风格也不一样 (如手机买个普通能用的就行, 但衣服都要买上千块的名牌), 也要区分存储.
类似于User2ItemTrigger, 我们也建立了 Item2ItemTrigger 表. 联合主键为itemId,triggerType,triggerId.
第一个Item 是泛指品牌, 类目这种, 第二个才是商品.
# itemTrigger2item 数据表准备
为了保证召回结果的多样性, 准备这部分数据时也会进行截断, 比如一级类目, 同一个一级类目下可能有上万个商品, 一般按个数 =50 5050 截断.
那么问题可以抽象为 <trigger,{item}> 二元组中, item 集合过大, 舍弃谁留下谁, 怎么做决策呢?
可以考虑这个公式:
b a n d i t _ c t r = { c l i c k n , p v < n c l i c k p v − 1 n , otherwise bandit_ctr =
{clickn,clickpv−1n,amp;pvamp;otherwiselt;n{clickn,amp;pvlt;nclickpv−1n,amp;otherwise
bandit_ctr={nclick,pvclick−n1,pv<notherwise
这个公式有三方面的考虑:
- 当曝光不充分时, ctr 是不稳定的, 所以不用 pv 作分母.
- 当内容的 ctr 低于1 n \frac 1 nn1时, 会变为负数, 被淘汰掉.
- 其他情况下, ctr 高的就会被优先召回.
trigger 是链接 userTrigger 与 itemTrigger 的桥梁.
# 在线召回
上面提到的信息是可以一次准备多次复用的, 并且量是很大的, 像 i2i 的召回表Item2ItemTrigger可以多达几百亿行数据. 所以一般离线算好.
在线系统做了哪些事情呢? 是以下三件.
# userTrigger 查询
收到客户端请求后, 根据 userId, 查出该 user 下的若干个 userTrigger.
# itemTrigger 召回
通过上一步 userTrigger 中的 trigger, 来找到 itemTrigger. 通过此步查询, 我们得到了若干个商品 (比如说 2000 个).
# 注意事项
需要注意的是 userTrigger 间的优先级和召回结果的丰富度.
- 优先级 同一 user 的 userTrigger 有很多, 可以区分优先级, 优先召回重要的. 比如用户在 A 类目下点了一个商品, 而在 B 类目下点了很多商品, 那么有关 B 的 userTrigger 优先级更高
- 丰富度 我们希望召回的 itemTrigger 中 trigger 也尽量丰富, 所以可以控制一下各 trigger 的占比.
- 得分计算 足够精细的话, 也可以算一下得分. (1) m a t c h S c o r e = t r i g g e r S c o r e ∗ u s e r T r i g g e r S c o r e ∗ i t e m T r i g g e r S c o r e matchScore=triggerScoreuserTriggerScoreitemTriggerScore \tag 1matchScor**e=triggerScor**e∗userTriggerScor**e∗itemTriggerScor**e(1), 就是 userId 与 itemId 的匹配得分啦.
# 过滤最近已看
近段时间推荐系统已经给用户甲推荐过商品 A, 甲点进去看了, 那么此时就不需要再重复推荐这个 A 商品了.
# 模型排序
详见参考 [2].
简述中我们提到了, 如果召回商品过多, 并且很多商品的相关度得分相同, 就必须要进行合理的排序. 因为用户不可能把相关的上万个商品都浏览一遍, 他们通常只会关注排在前几页的商品. 排序中也要关注推荐商品的质量, 虽然一个商品在兴趣方面挺吻合, 但差评很多或者销量很差, 也会把它排在后面.
推荐系统使用一段时间后, 就可以通过真实的用户点击行为来训练排序模型啦. 常用的是逻辑回归 LR 等. 不少做推荐的会吹嘘用到的特征是千万级别乃至上亿, 人们听到就会觉得好厉害啊. 其实不然. 他们只是把具有枚举值的特征给展开了而已. 商品 id, 卖家 id, 这些本身就是上亿级别的量. 对于这种稀疏的特征, LR 还可以处理, 换做决策树 / GBDT 等, 就歇菜了.
# 多目标
推荐系统的排序是有依据的. 我们的目标不同时, 推荐结果也会随之不同. 比如我们期望通过该推荐系统提升销量, 排序时就会着重考虑商品的火爆程度; 期望的是成交额, 就会着重考虑商品价格. 当然了, 也可以各个因素综合考虑, 结合 ctr 共同决定排序结果.
# 展示打散
为了避免推荐结果中高度相似的商品扎堆出现, 需要把它们打散, 类似洗牌一样. 按照类目打散是个不错的主意.
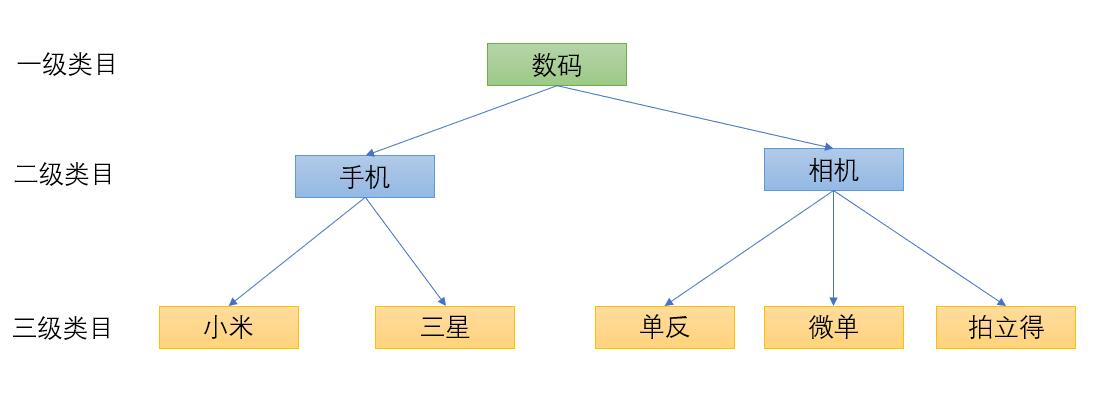
figure 商品类目层级举例
于是, 我们就可以按照类目维度对其进行打散.
这一步做的再精细一点, 就是按triggerName,triggerId为依据进行打散了.
# 2.5 bandit 探索
推荐的商品是与用户浏览行为相关的, 而用户能看到的商品又是与系统推荐相关的, 长此以往, 推荐结果越来越狭隘, 我们需要帮助用户发现一些新的东西, 拓展兴趣.
详见 bandit, 多臂赌博机中的探索 - 利用模型 (opens new window)
# 3. 推荐效果评价
# 3.1 投放前评价
- 准确率召回率 太常用了, 此处略过, 但跟普通的分类问题不一样, 召回结果那么多, 人工标也不合理, 难以实施.
- nDCG 可以参考我的博文, nDCG 排序模型评价指标 (opens new window)
# 3.2 投放后效果评价
系统投入使用以后, 就会拿到各种真实数据, 看看 ctr 什么的满不满足预期. ctr 又可以分为pvctr (推 荐 结 果 点 击 数 推 荐 结 果 曝 光 数 \frac {推荐结果点击数}{推荐结果曝光数}推荐结果曝光数推荐结果点击数) 和 uvctr(推 荐 结 果 点 击 人 数 推 荐 结 果 曝 光 人 数 \frac {推荐结果点击人数}{推荐结果曝光人数}推荐结果曝光人数推荐结果点击人数).
也可以 AB 测试, 通过实验验证心中的各种方案.
# 4. 冷启动
# 4.1 新用户
推荐结果依赖用户行为, 那么对于新用户, 召回结果为 0 或者过少, 可以用热门商品来做返回. 等过段时间积累到该用户的足够行为时, 就可以召回到更多结果了.
# 4.2 新商品
上架新商品, 没有足够的用户行为可以使用模型去预估商品热度等. 可以用充分曝光的商品做样本来训练网络.
# 其他特征
# 实时相关
通常, 各种数据我们都是离线用 hadoop 之类的隔天批处理计算的. 但若能捕捉到用户几分钟前, 几秒前的点击行为, 充分利用起来, 来影响召回与排序, 效果提升也是很明显的. 那就需要用_消息队列 + 实时计算来实时解析日志_.
# context 相关
c o n t e x t contextcontext 是指用户与产品交互时的情景特征. 如 时间, 地点, 用户正在进行的活动, 用户的情绪 等.
这些信息对推荐也是有益的.
# 神经网络进阶
通过以上处理, 一个效果良好的推荐系统就成型了. 再往高级上靠, 就可以使用神经网络建模. 关注用户的点击情况和点击序列, 各种学习 各种 embedding. 进而影响召回和排序.
# 相关 FAQ
Q: 搜索与推荐的区别是什么? A: 区别就是有没有考虑个性化. 推荐的根本就是 给一个候选池, 挑出用户最感兴趣的东西. 完全可以通过 tf-idf 等常规搜索确定候选池后, 再进行个性化展现.
Q: 推荐系统都是这个套路么? A: 大致如此. 推荐系统可以分为三种:
- user2user 比如 qq 上 "你可能认识的人" 这种推荐
- use2item. "向用户推荐电影, 美食, 商品" 这种. 本文讲的就是后者, 它用处更广泛一点.
- item2item 用户进入了商品详情页, 那么看完之后可以在底部在搞一个相似商品的推荐.
# 参考
- 我的 blog, 推荐系统中的 match 阶段 (opens new window) .
- 我的 blog, 推荐系统的 rank 模型 (opens new window)
全文完
本文由 简悦 SimpRead (opens new window) 优化,用以提升阅读体验
使用了 全新的简悦词法分析引擎 beta,点击查看 (opens new window)详细说明
文章目录 (opens new window)1. 简述 (opens new window)2. 分阶段讨论 (opens new window)离线数据准备 (opens new window)协同数据 (opens new window)特征数据 (opens new window)itemTrigger2item 数据表准备 (opens new window)在线召回 (opens new window)userTrigger 查询 (opens new window)itemTrigger 召回 (opens new window)注意事项 (opens new window)过滤最近已看 (opens new window)模型排序 (opens new window)多目标 (opens new window)展示打散 (opens new window)2.5 bandit 探索 (opens new window)3. 推荐效果评价 (opens new window)3.1 投放前评价 (opens new window)3.2 投放后效果评价 (opens new window)4. 冷启动 (opens new window)4.1 新用户 (opens new window)4.2 新商品 (opens new window)其他特征 (opens new window)实时相关 (opens new window)context 相关 (opens new window)神经网络进阶 (opens new window)相关 FAQ (opens new window)参考 (opens new window)