
对于一个初学者来说,学习存储引擎最好的办法就是亲身参与一个存储引擎的编写,但是普通人很难有机会,存储引擎不像是普通的应用程序,编写工业级别的存储引擎的机会,一般只会在数据库公司/部门或者某几个高校中,那么自己造轮子就是一个很好的办法。自己造轮子,不可能只看一些理论,必须参考现成的存储引擎,故需要对现在的存储引擎的情况做一个调查。调查从以下几个指标进行:
- 编程语言
- 代码规模
- 资料丰富程度
这些指标影响着学习这些存储引擎的效率。倘若存储引擎所用的编程语言是你不擅长的语言,那么学习、使用它本身还需要额外的成本;代码规模不宜过大,让初学者去阅读上百万,上十万规模代码的项目是不现实的,到目前为止,PostrgeSQL就有135万行代码,存储引擎部分肯定也不少,直接阅读它是不现实的,我去找猫咪借8条命也不够用;资料分为文档、书本、注释,资料丰富程度也影响着学习效率,代码的很多地方浓缩了很多信息量,直接阅读代码且没有相关经验的话很难理解代码的思路,丰富易读的资料能够让学习者如虎添翼,使得学习者可以以一个更高的视角去阅读代码。
目前存储引擎所使用的语言集中在三种:C、C++和Go,其它语言的存储引擎有,但是数量偏少,比如说使用Java的HBase,我们暂且不去思考为什么,只是关注于这个事实,从而得出一个结论:学习存储引擎,最好要懂得使用C/C++或Go中的至少一个。
对于初学者,代码规模在5000行以下是比较合适的,当然这里的代码是指核心代码,不包括一些脚本、测试、benchmark代码。这里的代码规模以选择存储引擎的特定版本为主,可能一些存储引擎的代码规模已经在10000行以上了,但是它的早期可用版本,在5000行以下,那么这也是合适的。代码行数也有两种,一种是整体代码行数,一种是有效代码行数,两者的区别是后者只统计能被编译器识别的部分,还需要除去头文件,注释是不计入的。整体代码行数使用Shell[1]命令进行统计,有效代码函数使用jetbrains的Statistic插件[2]进行统计。
对于资料丰富程度,一般有文档、书本、注释,大多数成熟的存储引擎都有自己的文档,再加上互联网上其它前辈对它的研究成果,可以作为参考。有书专门讲解的存储引擎比较少,一般书本比较系统,但是未必写得好。很多开发者写代码很认真,不仅写了代码还写了许多注释,写过代码的同学都知道,写代码很爽,写注释、文档却是一件很费力的事情,注释,代表着开发者对代码思路的见解,也有很多参考价值。最后阅读知乎回答、和有相关经验的知乎用户交流,也是一种了解存储引擎的方式。
下面介绍一些开源的存储引擎项目。该文章将随着我对它们了解的深入而不断更新。**想造轮子的童鞋可以联系我,咱们互相交流交流!**文章封面来自机核网[3]。
# boltdb
boltdb是一个参考自LMDB的存储引擎,作者在早期的时候直接将LMDB的代码复杂到项目中,加上注释,然后编写成Go的代码。目前已经封存,最后的提交时间为2018年3月3日,其fork版本被etcd维护为bbolt (opens new window),并应用与分布式存储etcd中,etcd作者是阿里巴巴90后工程师李响[4]。
它具备以下几个特征:
- 使用B+树作为索引
- 支持B+树嵌套(subbucket)
- 支持事务
- 支持持久化
- 使用mmap从磁盘中读取数据
- 使用freelist进行空间回收(不进行compact)
指标方面情况如下:
编程语言:纯Go编写(Go:99%,Makefile:0.1%)
代码行数:
截至最新的commit (opens new window),提交于2018年3月3日
- 整体代码行数(Go)12426行
- 有效代码行数9060行。
第一个稳定版本data/v1 (opens new window),发布于2014年4月12日
- 整体代码行数5798行
- 有效代码行数4197行。
Alpha版本 (opens new window),发布于2014年2月18日
- 整体代码行数3911行
- 有效代码行数2700行。
资料方面
文档方面
- 官方README (opens new window):介绍了boltdb的API,介绍了一些数据库、存储引擎,简要地概况核心源代码文件的功能和设计,以及一些阅读源码建议
- PingCAP员工 的博客文章:boltbd源码分析 (opens new window),简要地介绍了一下boltdb的存储、事务
- 公众号codedump的网络日志中的boltdb系列 (opens new window),从索引讲起,还是比较细致
- 一位以注销用户对bolt优缺点的看法:BoltDB的优点与缺点 (opens new window)
- 同名公众号系列文章boltdb源码导读 (opens new window),知乎文章也有,可以翻翻,讲解了数据组织、索引设计、事务实现
- Github用户ZhengHe-MD的源码阅读项目learn bolt (opens new window)
书本方面
没有出版书,只有网络书籍,用户jaydenwen123的自底向上分析BoltDB源码 (opens new window),相当全面细致,不过我个人不赞同自底向上是很好的写书方式,尤其是对初学者而言,我们需要先了解该技术背景下所面临的问题,再才能去很好地理解技术本身,故自顶(实际问题)向下,发现问题、分析问题、学习技术、解决问题、总结优缺点才是更符合人性的编写方式,但是此书还是有很大的参考价值的。
作者录制的相关网络视频:
注释方面
- 除了原项目的注释以外没有发现第三方注释
- 原项目注释较为齐全,很多变量、函数都有简要的说明
总结一下,boltdb代码量小,功能齐全,且其fork版本已经被应用到了工业级别的项目中,也已经封存,资料丰富,讨论研究的人也很多,故是学习的最佳对象之一,可惜我不太会go~对于熟悉go的同学来说是再好不过的项目了。
# sqlite
著名嵌入式关系型数据库,被大量应用于Android系统中,纯C编写,代码注释很齐全,准确地说这不是一个存储引擎,是一个完整的项目,但是可以抽取其中后端的部分来学习。作者写的一篇关于为什么sqlite使用C进行编写的文章,Why Is SQLite Coded In C (opens new window) 写的很好。下面是sqlite的架构:
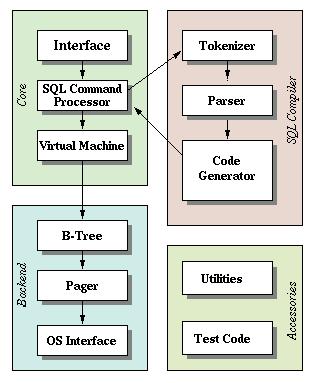
它具备以下特性:
- 采用B树作为索引,但是听说LSM也可,有模块可选择,不过是比较新的版本
- 支持持久化,具体机制不了解
- 支持事务
- 支持WAL
各个指标方面:
编程语言:使用纯C编写,使用TCL进行测试(C:87.9%,TCL:6.8%)
代码行数,来自于SQLite官方时间线[5]
截至最新的commit,提交于2021年7月21日
- 整体代码:367229[.c] + 19885[.h] = 397114
- 有效代码:238904[.c] + 5343[.h] = 244247
第一个版本Version 1.0 (CVS 499) (opens new window),提交于2000年8月17日
- 整体代码:15181[.c] + 757[.h] = 15938
- 有效代码:10633[.c] + 238[.h] = 10871
第一次完整的提交initial check-in of the new version (CVS 1) (opens new window),提交于2000年5月29日
- 整体代码:10865[.c] + 638[.h] = 11503
- 有效代码:7627[.c] + 172[.h] = 7799
资料方面
文档方面:
- 官方的文档 (opens new window),纯英文,详细介绍了SQLite的各个方面
- Let's Build a Simple Database (opens new window):cstack编写的基于sqlite的教程,写得非常好,强烈推荐!!!从一个简单的问题,上手给读者演示如何解决问题,解决好后进行测试评价,在以后的篇幅中以这个问题为入口继续这个过程。书栈网把原项目进行了整理,你可以在它们的网站上[6]阅读。
- 构建简单的数据库 (opens new window):Let's Build a Simple:Let's Build a Simple Database的中文翻译,可惜翻译不完全,只到第8篇,还有一点点小瑕疵,不过还是很好的,不习惯英文的可以看这个。
- 写的答案:如何学习sqlite源码 (opens new window),介绍了一下答主自己学习sqlite所造的轮子,还推荐了很多资料,写得很详细,我都没得写咯。
书本方面,这些在张原嘉的回答中都有详细的描述
注释方面
- 听说官方项目的注释很详尽,比书的内容都多~[7]
总结一下,相比boltdb,SQLite更有名,即使不是数据库、分布式行业从业者,也听过SQLite的鼎鼎大名,其代码质量是经受过考验的。缺点是代码规模略大,优点是资料比较多,讨论研究的人也挺多的吧,想学习当前的SQLite是不可能的,从第一个版本看起还是有可能的。
# key-value-system
这不是什么著名存储引擎,这只是一个玩具项目,应该是用作毕设的,我在我的Github的活动时间线[8]中发现了它,那个时候我正愁毕设写什么,看见它就对存储引擎起了兴趣,它索引数据结构落后,甚至没有完备的持久化机制和压缩操作,但是它还是给了我很多启发。虽然没有封存,但是作者已不再开发,且很难联系上作者。
它具备以下特性:
- 采用hashtable作为索引数据结构
- 在索引下设计了一个缓冲池
- 缓冲池支持持久化(索引不支持)
各个指标方面:
编程语言:纯C编写(C:100%)
代码行数,没有发布过版本:
最后的commit (opens new window)提交与2012年2月26日
- 整体行数:3925[.c] + 653[.h] = 4578
- 有效行数:3061[.c] + 165[.h] = 3226
去掉测试代码:
- 整体行数:941[.c] + 181[.h] = 1122
- 有效行数:735[.c] + 51[.h] = 786
资料方面
- 只有官方文档 (opens new window):分为使用、性能测试、设计文档,虽然不多,但是写得很全面,很到位
总结一下,这是一个很简单,甚至有些过时的存储引擎,但是它很简单,代码量住够小,但是缓冲池的设计理解起来还是有点难度的。另我吃惊的是,测试代码所占的比重是如此之高,在75%以上!!着实让我感叹,测试才是数据库最重要的部分!这里推荐一下我的毕设成果EdithDB (opens new window),由于本人水平有限,写的项目漏洞百出,文档的话就是我的毕业论文,暂时没有公布,因为觉得没有人会看~
# 接下来的更新计划
- LMDB (opens new window)
- leveldb (opens new window)
- nessdb (opens new window)
- redis (opens new window)
- badger (opens new window)
- rosedb (opens new window)
- Tokyo Cabinet (opens new window)
# 参考
- ^find . -name "*.c"|xargs wc -l|grep "total"|awk '{print $1}'
- ^Statistic是一个专门用来统计代码行数的插件 https://plugins.jetbrains.com/plugin/4509-statistic
- ^游戏开发设计心得分享专题封面 https://www.gcores.com/collections/64
- ^阿里巴巴李响加入 CNCF 技术监督委员会 https://www.infoq.cn/article/z1fl-LX3o2yGdIqG12S1
- ^SQLite源代码时间线 https://www.sqlite.org/cgi/src/timeline
- ^bookstack:[英文] DB Tutorial https://www.bookstack.cn/read/db_tutorial/README.md
- ^还是来源于张原嘉的回答 https://www.zhihu.com/question/22819578/answer/62544197
- ^当你进入github.com时,会推荐关注的人的收藏动态
发布于 07-22
# 文章被以下专栏收录
