
张彦飞
这个问题非常不错,由于 side car 模式的兴起,感觉本机网络 IO 用的越来越多了,所以我特地把该问题挖出来答一答。不过我想把这个问题再丰富丰富,讨论起来更带劲!127.0.0.1 本机网络 IO 需要经过网卡吗?数据包在内核中是个什么走向,和外网发送相比流程上有啥差别?用本机 ip(例如 192.168.x.x) 和用 127.0.0.1 性能上有差别吗?这里先直接把结论抛出来。127.0.0.1 本机网络 IO 不经过网卡本机网络 IO 过程除了不过网卡,其它流程如内核协议栈还都得走。用本机 ip(例如 192.168.x.x) 和用 127.0.0.1 性能没有大差别内容来源于本人公 - 众 - 号: 开发内功修炼, 欢迎关注!另外我把我对网络是如何收包的,如何使用 CPU,如何使用内存的对于内存的都深度分析了一下,还增加了一些性能优化建议和前沿技术展望等,最终汇聚出了这本《理解了实现再谈网络性能》。在此无私分享给大家。 下载链接传送门:《理解了实现再谈网络性能》 (opens new window)
好了,继续讨论今天的问题!一、跨机网路通信过程在开始讲述本机通信过程之前,我们还是先回顾一下跨机网络通信。1.1 跨机数据发送从 send 系统调用开始,直到网卡把数据发送出去,整体流程如下:
下载链接传送门:《理解了实现再谈网络性能》 (opens new window)
好了,继续讨论今天的问题!一、跨机网路通信过程在开始讲述本机通信过程之前,我们还是先回顾一下跨机网络通信。1.1 跨机数据发送从 send 系统调用开始,直到网卡把数据发送出去,整体流程如下: 在这幅图中,我们看到用户数据被拷贝到内核态,然后经过协议栈处理后进入到了 RingBuffer 中。随后网卡驱动真正将数据发送了出去。当发送完成的时候,是通过硬中断来通知 CPU,然后清理 RingBuffer。不过上面这幅图并没有很好地把内核组件和源码展示出来,我们再从代码的视角看一遍。
在这幅图中,我们看到用户数据被拷贝到内核态,然后经过协议栈处理后进入到了 RingBuffer 中。随后网卡驱动真正将数据发送了出去。当发送完成的时候,是通过硬中断来通知 CPU,然后清理 RingBuffer。不过上面这幅图并没有很好地把内核组件和源码展示出来,我们再从代码的视角看一遍。 等网络发送完毕之后。网卡在发送完毕的时候,会给 CPU 发送一个硬中断来通知 CPU。收到这个硬中断后会释放 RingBuffer 中使用的内存。
等网络发送完毕之后。网卡在发送完毕的时候,会给 CPU 发送一个硬中断来通知 CPU。收到这个硬中断后会释放 RingBuffer 中使用的内存。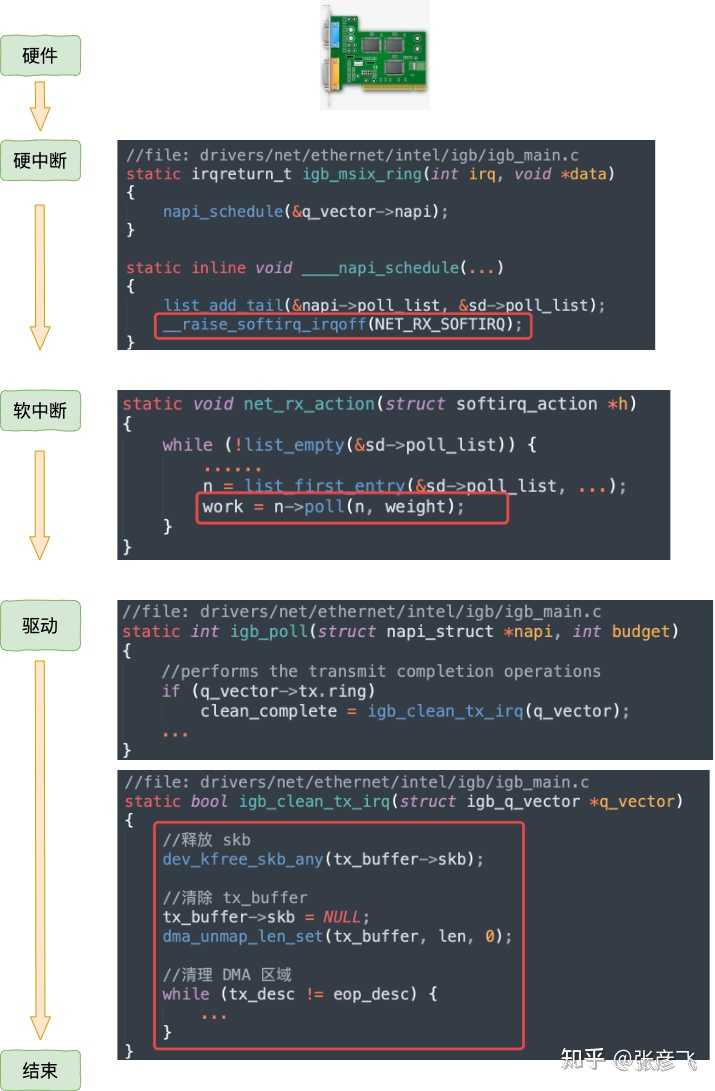 更详细的分析过程参见:25 张图,一万字,拆解 Linux 网络包发送过程mp.weixin.qq.com
更详细的分析过程参见:25 张图,一万字,拆解 Linux 网络包发送过程mp.weixin.qq.com (opens new window)1.2 跨机数据接收当数据包到达另外一台机器的时候,Linux 数据包的接收过程开始了。
(opens new window)1.2 跨机数据接收当数据包到达另外一台机器的时候,Linux 数据包的接收过程开始了。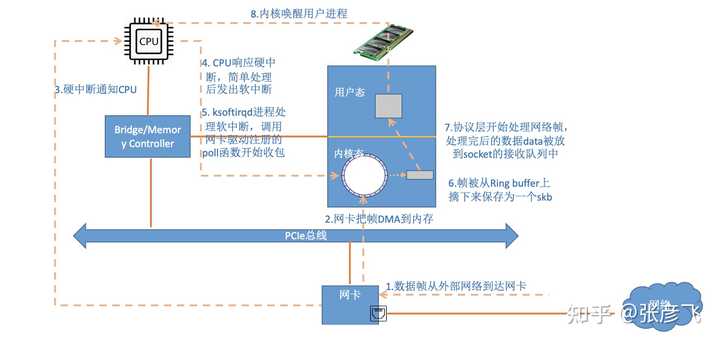 当网卡收到数据以后,向 CPU 发起一个中断,以通知 CPU 有数据到达。当 CPU 收到中断请求后,会去调用网络驱动注册的中断处理函数,触发软中断。ksoftirqd 检测到有软中断请求到达,开始轮询收包,收到后交由各级协议栈处理。当协议栈处理完并把数据放到接收队列的之后,唤醒用户进程(假设是阻塞方式)。我们再同样从内核组件和源码视角看一遍。
当网卡收到数据以后,向 CPU 发起一个中断,以通知 CPU 有数据到达。当 CPU 收到中断请求后,会去调用网络驱动注册的中断处理函数,触发软中断。ksoftirqd 检测到有软中断请求到达,开始轮询收包,收到后交由各级协议栈处理。当协议栈处理完并把数据放到接收队列的之后,唤醒用户进程(假设是阻塞方式)。我们再同样从内核组件和源码视角看一遍。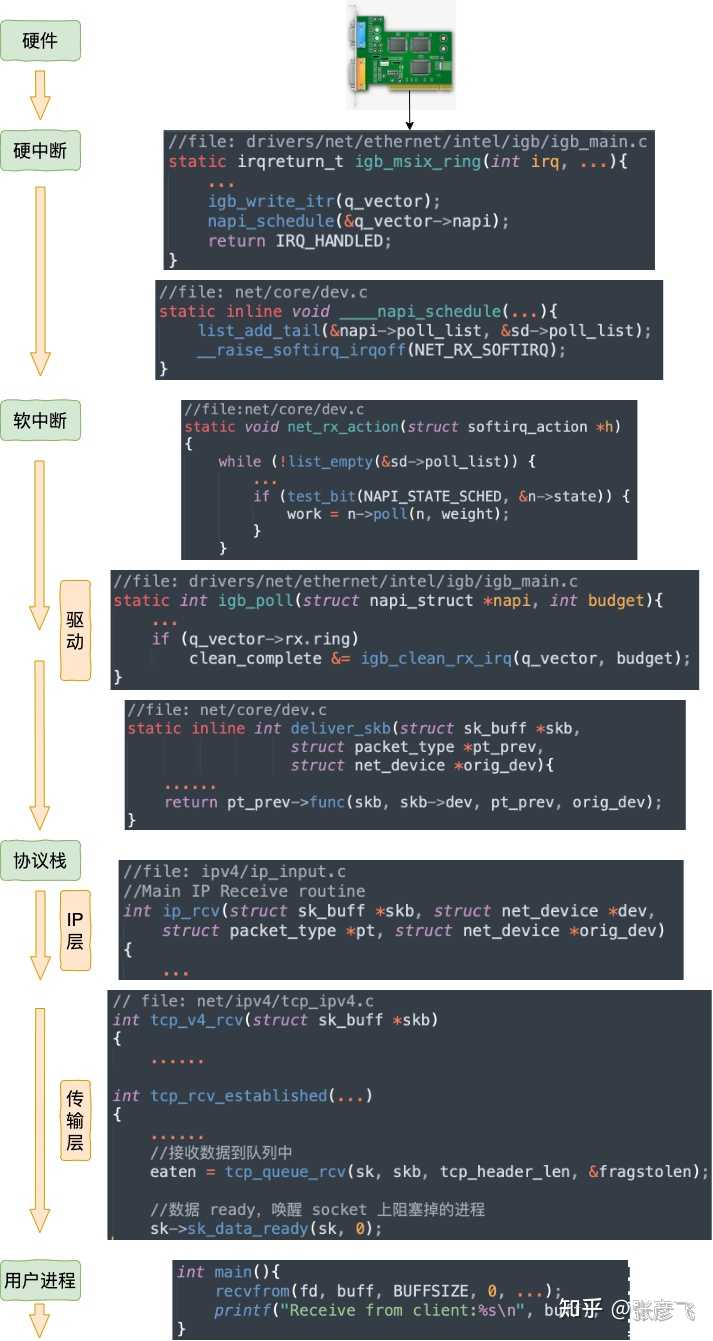 详细的接收过程参见这篇文章:图解 Linux 网络包接收过程 (opens new window)**1.3 跨机网络通信汇总
详细的接收过程参见这篇文章:图解 Linux 网络包接收过程 (opens new window)**1.3 跨机网络通信汇总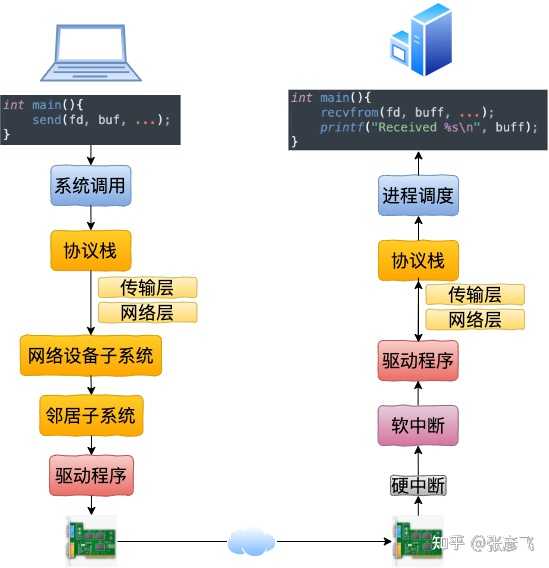 二、本机发送过程在第一节中,我们看到了跨机时整个网络发送过程(嫌第一节流程图不过瘾,想继续看源码了解细节的同学可以参考 拆解 Linux 网络包发送过程 (opens new window)) 。在本机网络 IO 的过程中,流程会有一些差别。为了突出重点,将不再介绍整体流程,而是只介绍和跨机逻辑不同的地方。有差异的地方总共有两个,分别是路由和驱动程序**。2.1 网络层路由发送数据会进入协议栈到网络层的时候,网络层入口函数是 ip_queue_xmit。在网络层里会进行路由选择,路由选择完毕后,再设置一些 IP 头、进行一些 netfilter 的过滤后,将包交给邻居子系统。
二、本机发送过程在第一节中,我们看到了跨机时整个网络发送过程(嫌第一节流程图不过瘾,想继续看源码了解细节的同学可以参考 拆解 Linux 网络包发送过程 (opens new window)) 。在本机网络 IO 的过程中,流程会有一些差别。为了突出重点,将不再介绍整体流程,而是只介绍和跨机逻辑不同的地方。有差异的地方总共有两个,分别是路由和驱动程序**。2.1 网络层路由发送数据会进入协议栈到网络层的时候,网络层入口函数是 ip_queue_xmit。在网络层里会进行路由选择,路由选择完毕后,再设置一些 IP 头、进行一些 netfilter 的过滤后,将包交给邻居子系统。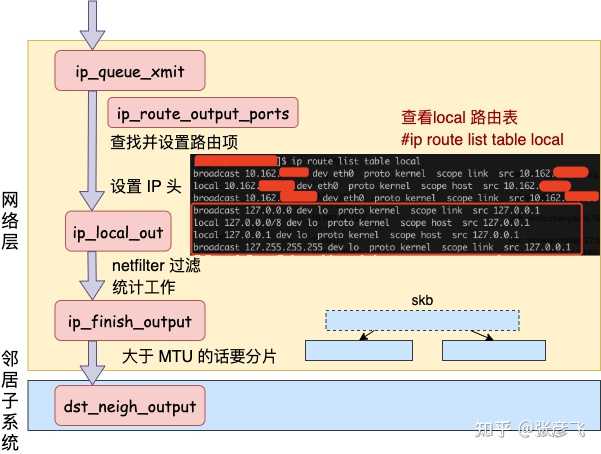 对于本机网络 IO 来说,特殊之处在于在 local 路由表中就能找到路由项,对应的设备都将使用 loopback 网卡,也就是我们常见的 lo。我们来详细看看路由网络层里这段路由相关工作过程。从网络层入口函数 ip_queue_xmit 看起。
对于本机网络 IO 来说,特殊之处在于在 local 路由表中就能找到路由项,对应的设备都将使用 loopback 网卡,也就是我们常见的 lo。我们来详细看看路由网络层里这段路由相关工作过程。从网络层入口函数 ip_queue_xmit 看起。//file: net/ipv4/ip_output.c int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl) { //检查 socket 中是否有缓存的路由表 rt = (struct rtable *)__sk_dst_check(sk, 0); if (rt == NULL) { //没有缓存则展开查找 //则查找路由项, 并缓存到 socket 中 rt = ip_route_output_ports(...); sk_setup_caps(sk, &rt->dst); }查找路由项的函数是 ip_route_output_ports,它又依次调用到 ip_route_output_flow、__ip_route_output_key、fib_lookup。调用过程省略掉,直接看 fib_lookup 的关键代码。//file:include/net/ip_fib.h static inline int fib_lookup(struct net *net, const struct flowi4 *flp, struct fib_result *res) { struct fib_table *table; table = fib_get_table(net, RT_TABLE_LOCAL); if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF)) return 0; table = fib_get_table(net, RT_TABLE_MAIN); if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF)) return 0; return -ENETUNREACH; }在 fib_lookup 将会对 local 和 main 两个路由表展开查询,并且是先查 local 后查询 main。我们在 Linux 上使用命令名可以查看到这两个路由表, 这里只看 local 路由表(因为本机网络 IO 查询到这个表就终止了)。#ip route list table local local 10.143.x.y dev eth0 proto kernel scope host src 10.143.x.y local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1从上述结果可以看出,对于目的是 127.0.0.1 的路由在 local 路由表中就能够找到了。fib_lookup 工作完成,返回__ip_route_output_key 继续。//file: net/ipv4/route.c struct rtable *__ip_route_output_key(struct net *net, struct flowi4 *fl4) { if (fib_lookup(net, fl4, &res)) { } if (res.type == RTN_LOCAL) { dev_out = net->loopback_dev; ... } rth = __mkroute_output(&res, fl4, orig_oif, dev_out, flags); return rth; }对于是本机的网络请求,设备将全部都使用 net->loopback_dev, 也就是 lo 虚拟网卡。接下来的网络层仍然和跨机网络 IO 一样,最终会经过 ip_finish_output,最终进入到 邻居子系统的入口函数 dst_neigh_output 中。本机网络 IO 需要进行 IP 分片吗?因为和正常的网络层处理过程一样会经过 ip_finish_output 函数。在这个函数中,如果 skb 大于 MTU 的话,仍然会进行分片。只不过 lo 的 MTU 比 Ethernet 要大很多。通过 ifconfig 命令就可以查到,普通网卡一般为 1500,而 lo 虚拟接口能有 65535。
在邻居子系统函数中经过处理,进入到网络设备子系统(入口函数是 dev_queue_xmit)。2.2 本机 IP 路由开篇我们提到的第三个问题的答案就在前面的网络层路由一小节中。但这个问题描述起来有点长,因此单独拉一小节出来。问题: 用本机 ip(例如 192.168.x.x) 和用 127.0.0.1 性能上有差别吗?前面看到选用哪个设备是路由相关函数 __ip_route_output_key 中确定的。//file: net/ipv4/route.c struct rtable *__ip_route_output_key(struct net *net, struct flowi4 *fl4) { if (fib_lookup(net, fl4, &res)) { } if (res.type == RTN_LOCAL) { dev_out = net->loopback_dev; ... } rth = __mkroute_output(&res, fl4, orig_oif, dev_out, flags); return rth; }这里会查询到 local 路由表。# ip route list table local local 10.162.*.* dev eth0 proto kernel scope host src 10.162.*.* local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1很多人在看到这个路由表的时候就被它给迷惑了,以为上面 10.162*.* 真的会被路由到 eth0(其中 10.162.. 是我的本机局域网 IP,我把后面两段用 * 号隐藏起来了)。但其实内核在初始化 local 路由表的时候,把 local 路由表里所有的路由项都设置成了 RTN_LOCAL,不仅仅只是 127.0.0.1。这个过程是在设置本机 ip 的时候,调用 fib_inetaddr_event 函数完成设置的。static int fib_inetaddr_event(struct notifier_block *this, unsigned long event, void *ptr) { switch (event) { case NETDEV_UP: fib_add_ifaddr(ifa); break; case NETDEV_DOWN: fib_del_ifaddr(ifa, NULL); //file:ipv4/fib_frontend.c void fib_add_ifaddr(struct in_ifaddr *ifa) { fib_magic(RTM_NEWROUTE, RTN_LOCAL, addr, 32, prim); }所以即使本机 IP,不用 127.0.0.1,内核在路由项查找的时候判断类型是 RTN_LOCAL,仍然会使用 net->loopback_dev。也就是 lo 虚拟网卡。为了稳妥起见,飞哥再抓包确认一下。开启两个控制台窗口,一个对 eth0 设备进行抓包。因为局域网内会有大量的网络请求,为了方便过滤,这里使用一个特殊的端口号 8888。如果这个端口号在你的机器上占用了,那需要再换一个。#tcpdump -i eth0 port 8888另外一个窗口使用 telnet 对本机 IP 端口发出几条网络请求。#telnet 10.162.*.* 8888 Trying 10.162.129.56... telnet: connect to address 10.162.129.56: Connection refused这时候切回第一个控制台,发现啥反应都没有。说明包根本就没有过 eth0 这个设备。再把设备换成 lo 再抓。当 telnet 发出网络请求以后,在 tcpdump 所在的窗口下看到了抓包结果。# tcpdump -i lo port 8888 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on lo, link-type EN10MB (Ethernet), capture size 65535 bytes 08:22:31.956702 IP 10.162.*.*.62705 > 10.162.*.*.ddi-tcp-1: Flags [S], seq 678725385, win 43690, options [mss 65495,nop,wscale 8], length 0 08:22:31.956720 IP 10.162.*.*.ddi-tcp-1 > 10.162.*.*.62705: Flags [R.], seq 0, ack 678725386, win 0, length 02.3 网络设备子系统网络设备子系统的入口函数是 dev_queue_xmit。简单回忆下之前讲述跨机发送过程的时候,对于真的有队列的物理设备,在该函数中进行了一系列复杂的排队等处理以后,才调用 dev_hard_start_xmit,从这个函数 再进入驱动程序来发送。在这个过程中,甚至还有可能会触发软中断来进行发送,流程如图: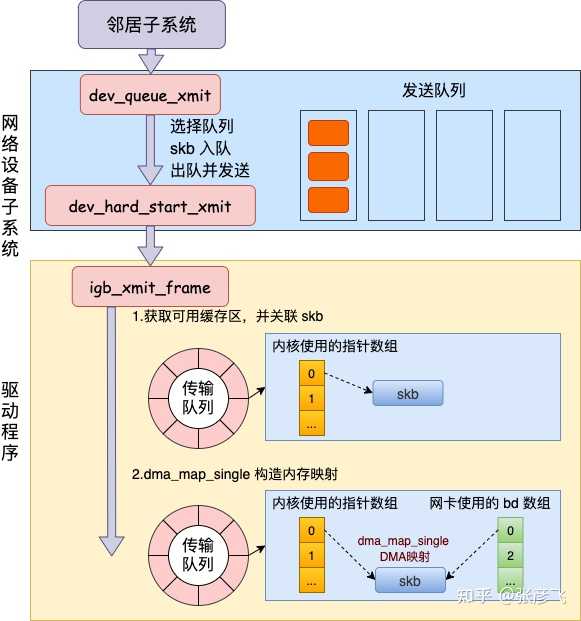 但是对于启动状态的回环设备来说(q->enqueue 判断为 false),就简单多了。没有队列的问题,直接进入 dev_hard_start_xmit。接着中进入回环设备的 “驱动” 里的发送回调函数 loopback_xmit,将 skb “发送”出去。
但是对于启动状态的回环设备来说(q->enqueue 判断为 false),就简单多了。没有队列的问题,直接进入 dev_hard_start_xmit。接着中进入回环设备的 “驱动” 里的发送回调函数 loopback_xmit,将 skb “发送”出去。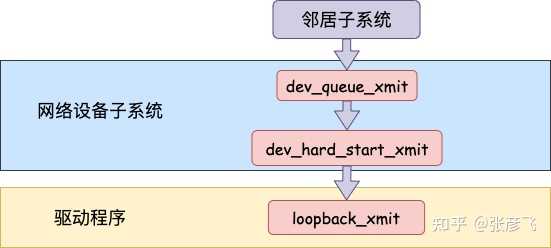 我们来看下详细的过程,从 网络设备子系统的入口 dev_queue_xmit 看起。
我们来看下详细的过程,从 网络设备子系统的入口 dev_queue_xmit 看起。//file: net/core/dev.c int dev_queue_xmit(struct sk_buff *skb) { q = rcu_dereference_bh(txq->qdisc); if (q->enqueue) {//回环设备这里为 false rc = __dev_xmit_skb(skb, q, dev, txq); goto out; } //开始回环设备处理 if (dev->flags & IFF_UP) { dev_hard_start_xmit(skb, dev, txq, ...); ... } }在 dev_hard_start_xmit 中还是将调用设备驱动的操作函数。//file: net/core/dev.c int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev, struct netdev_queue *txq) { //获取设备驱动的回调函数集合 ops const struct net_device_ops *ops = dev->netdev_ops; //调用驱动的 ndo_start_xmit 来进行发送 rc = ops->ndo_start_xmit(skb, dev); ... }2.3 “驱动” 程序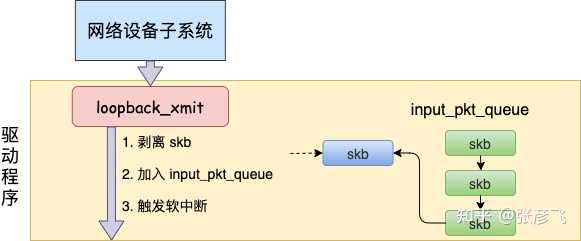 对于真实的 igb 网卡来说,它的驱动代码都在 drivers/net/ethernet/intel/igb/igb_main.c 文件里。顺着这个路子,我找到了 loopback 设备的 “驱动” 代码位置:drivers/net/loopback.c。 在 drivers/net/loopback.c
对于真实的 igb 网卡来说,它的驱动代码都在 drivers/net/ethernet/intel/igb/igb_main.c 文件里。顺着这个路子,我找到了 loopback 设备的 “驱动” 代码位置:drivers/net/loopback.c。 在 drivers/net/loopback.c//file:drivers/net/loopback.c static const struct net_device_ops loopback_ops = { .ndo_init = loopback_dev_init, .ndo_start_xmit= loopback_xmit, .ndo_get_stats64 = loopback_get_stats64, };所以对 dev_hard_start_xmit 调用实际上执行的是 loopback “驱动” 里的 loopback_xmit。为什么我把 “驱动” 加个引号呢,因为 loopback 是一个纯软件性质的虚拟接口,并没有真正意义上的驱动。//file:drivers/net/loopback.c static netdev_tx_t loopback_xmit(struct sk_buff *skb, struct net_device *dev) { //剥离掉和原 socket 的联系 skb_orphan(skb); //调用netif_rx if (likely(netif_rx(skb) == NET_RX_SUCCESS)) { } }在 skb_orphan 中先是把 skb 上的 socket 指针去掉了(剥离了出来)。注意,在本机网络 IO 发送的过程中,传输层下面的 skb 就不需要释放了,直接给接收方传过去就行了。总算是省了一点点开销。不过可惜传输层的 skb 同样节约不了,还是得频繁地申请和释放。接着调用 netif_rx,在该方法中 中最终会执行到 enqueue_to_backlog 中(netif_rx -> netif_rx_internal -> enqueue_to_backlog)。//file: net/core/dev.c static int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail) { sd = &per_cpu(softnet_data, cpu); ... __skb_queue_tail(&sd->input_pkt_queue, skb); ... ____napi_schedule(sd, &sd->backlog);在 enqueue_to_backlog 把要发送的 skb 插入 softnet_data->input_pkt_queue 队列中并调用 ____napi_schedule 来触发软中断。//file:net/core/dev.c static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi) { list_add_tail(&napi->poll_list, &sd->poll_list); __raise_softirq_irqoff(NET_RX_SOFTIRQ); }只有触发完软中断,发送过程就算是完成了。三、本机接收过程在跨机的网络包的接收过程中,需要经过硬中断,然后才能触发软中断。而在本机的网络 IO 过程中,由于并不真的过网卡,所以网卡实际传输,硬中断就都省去了。直接从软中断开始,经过 process_backlog 后送进协议栈,大体过程如图。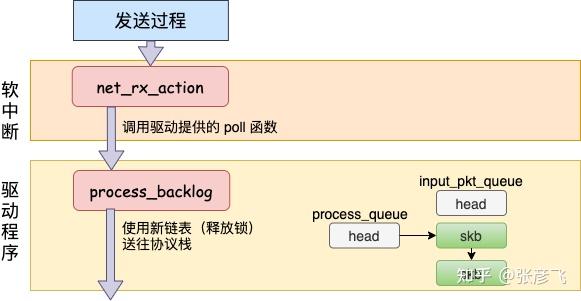 接下来我们再看更详细一点的过程。
在软中断被触发以后,会进入到 NET_RX_SOFTIRQ 对应的处理方法 net_rx_action 中(至于细节参见 图解 Linux 网络包接收过程 (opens new window)一文中的 3.2 小节)。
接下来我们再看更详细一点的过程。
在软中断被触发以后,会进入到 NET_RX_SOFTIRQ 对应的处理方法 net_rx_action 中(至于细节参见 图解 Linux 网络包接收过程 (opens new window)一文中的 3.2 小节)。//file: net/core/dev.c static void net_rx_action(struct softirq_action *h){ while (!list_empty(&sd->poll_list)) { work = n->poll(n, weight); } }我们还记得对于 igb 网卡来说,poll 实际调用的是 igb_poll 函数。那么 loopback 网卡的 poll 函数是谁呢?由于 poll_list 里面是 struct softnet_data 对象,我们在 net_dev_init 中找到了蛛丝马迹。//file:net/core/dev.c static int __init net_dev_init(void) { for_each_possible_cpu(i) { sd->backlog.poll = process_backlog; } }原来struct softnet_data 默认的 poll 在初始化的时候设置成了 process_backlog 函数,来看看它都干了啥。static int process_backlog(struct napi_struct *napi, int quota) { while(){ while ((skb = __skb_dequeue(&sd->process_queue))) { __netif_receive_skb(skb); } //skb_queue_splice_tail_init()函数用于将链表a连接到链表b上, //形成一个新的链表b,并将原来a的头变成空链表。 qlen = skb_queue_len(&sd->input_pkt_queue); if (qlen) skb_queue_splice_tail_init(&sd->input_pkt_queue, &sd->process_queue); } }这次先看对 skb_queue_splice_tail_init 的调用。源码就不看了,直接说它的作用是把 sd->input_pkt_queue 里的 skb 链到 sd->process_queue 链表上去。然后再看 __skb_dequeue, __skb_dequeue 是从 sd->process_queue 上取下来包来处理。这样和前面发送过程的结尾处就对上了,发送过程是把包放到了 input_pkt_queue 队列里。 最后调用 __netif_receive_skb 将数据送往协议栈。在此之后的调用过程就和跨机网络 IO 又一致了。送往协议栈的调用链是 __netif_receive_skb => __netif_receive_skb_core => deliver_skb 后 将数据包送入到 ip_rcv 中(详情参见图解 Linux 网络包接收过程 (opens new window)一文中的 3.3 小节)。网络再往后依次是传输层,最后唤醒用户进程。四、本机网络 IO 总结我们来总结一下本机网络 IO 的内核执行流程。
最后调用 __netif_receive_skb 将数据送往协议栈。在此之后的调用过程就和跨机网络 IO 又一致了。送往协议栈的调用链是 __netif_receive_skb => __netif_receive_skb_core => deliver_skb 后 将数据包送入到 ip_rcv 中(详情参见图解 Linux 网络包接收过程 (opens new window)一文中的 3.3 小节)。网络再往后依次是传输层,最后唤醒用户进程。四、本机网络 IO 总结我们来总结一下本机网络 IO 的内核执行流程。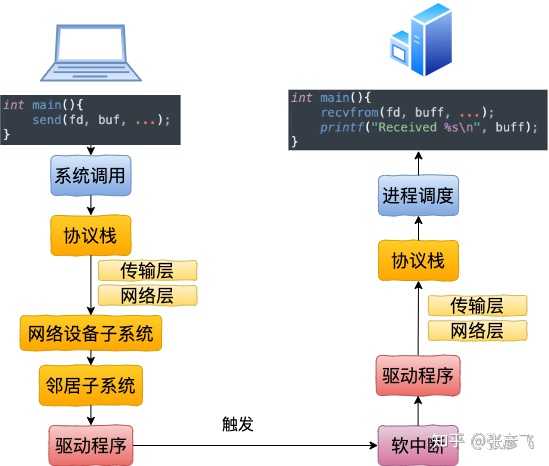 回想下跨机网络 IO 的流程是
回想下跨机网络 IO 的流程是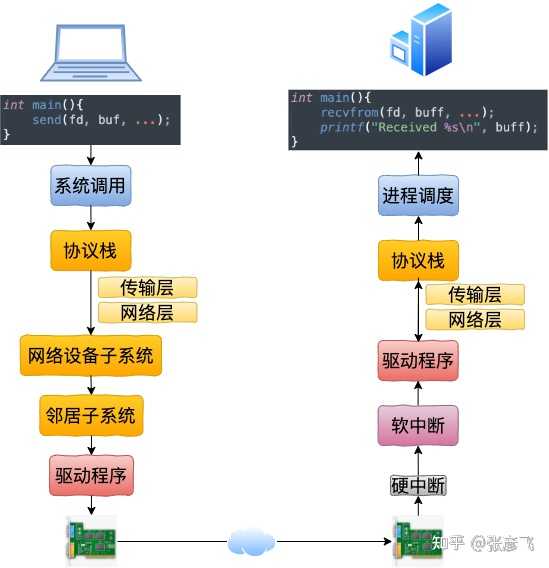 我们现在可以回顾下开篇的三个问题啦。1)127.0.0.1 本机网络 IO 需要经过网卡吗? 通过本文的叙述,我们确定地得出结论,不需要经过网卡。即使了把网卡拔了本机网络是否还可以正常使用的。2)数据包在内核中是个什么走向,和外网发送相比流程上有啥差别? 总的来说,本机网络 IO 和跨机 IO 比较起来,确实是节约了驱动上的一些开销。发送数据不需要进 RingBuffer 的驱动队列,直接把 skb 传给接收协议栈(经过软中断)。但是在内核其它组件上,可是一点都没少,系统调用、协议栈(传输层、网络层等)、设备子系统整个走了一个遍。连 “驱动” 程序都走了(虽然对于回环设备来说只是一个纯软件的虚拟出来的东东)。所以即使是本机网络 IO,切忌误以为没啥开销就滥用。3)用本机 ip(例如 192.168.x.x) 和用 127.0.0.1 性能上有差别吗? 很多人的直觉是走网卡,但正确结论是和 127.0.0.1 没有差别,都是走虚拟的环回设备 lo。
这是因为内核在设置 ip 的时候,把所有的本机 ip 都初始化 local 路由表里了,而且类型写死 RTN_LOCAL。在后面的路由项选择的时候发现类型是 RTN_LOCAL 就会选择 lo 了。还不信的话你也动手抓包试试!最后再提一下,业界有公司基于 ebpf 的 sockmap 和 sk redirect 功能研发了自己的 sockops 组件 (opens new window),用来加速 istio 架构中 sidecar 代理和本地进程之间的通信。通过引入 BPF,才算是绕开了内核协议栈的开销,原理如下。
我们现在可以回顾下开篇的三个问题啦。1)127.0.0.1 本机网络 IO 需要经过网卡吗? 通过本文的叙述,我们确定地得出结论,不需要经过网卡。即使了把网卡拔了本机网络是否还可以正常使用的。2)数据包在内核中是个什么走向,和外网发送相比流程上有啥差别? 总的来说,本机网络 IO 和跨机 IO 比较起来,确实是节约了驱动上的一些开销。发送数据不需要进 RingBuffer 的驱动队列,直接把 skb 传给接收协议栈(经过软中断)。但是在内核其它组件上,可是一点都没少,系统调用、协议栈(传输层、网络层等)、设备子系统整个走了一个遍。连 “驱动” 程序都走了(虽然对于回环设备来说只是一个纯软件的虚拟出来的东东)。所以即使是本机网络 IO,切忌误以为没啥开销就滥用。3)用本机 ip(例如 192.168.x.x) 和用 127.0.0.1 性能上有差别吗? 很多人的直觉是走网卡,但正确结论是和 127.0.0.1 没有差别,都是走虚拟的环回设备 lo。
这是因为内核在设置 ip 的时候,把所有的本机 ip 都初始化 local 路由表里了,而且类型写死 RTN_LOCAL。在后面的路由项选择的时候发现类型是 RTN_LOCAL 就会选择 lo 了。还不信的话你也动手抓包试试!最后再提一下,业界有公司基于 ebpf 的 sockmap 和 sk redirect 功能研发了自己的 sockops 组件 (opens new window),用来加速 istio 架构中 sidecar 代理和本地进程之间的通信。通过引入 BPF,才算是绕开了内核协议栈的开销,原理如下。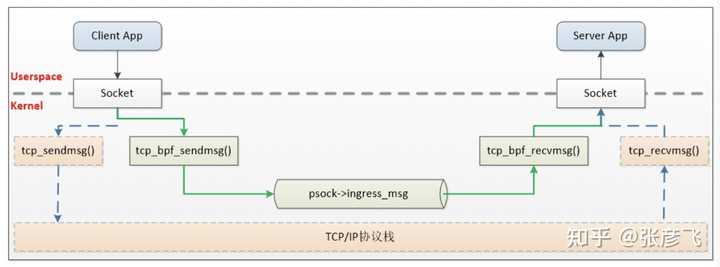 飞哥写了一本电子书。这本电子书是对网络性能进行拆解,把性能拆分为三个角度:CPU 开销、内存开销等。具体到某个角度比如 CPU,那我需要给自己解释清楚网络包是怎么从网卡到内核中的,内核又是通过哪些方式通知进程的。只有理解清楚了这些才能真正把握网络对 CPU 的消耗。对于内存角度也是一样,只有理解了内核是如何使用内存,甚至需要哪些内核对象都搞清楚,也才能真正理解一条 TCP 连接的内存开销。除此之外我还增加了一些性能优化建议和前沿技术展望等,最终汇聚出了这本《理解了实现再谈网络性能》。在此无私分享给大家。下载链接传送门:**《理解了实现再谈网络性能》 (opens new window)另外飞哥经常会收到读者的私信,询问可否推荐一些书继续深入学习内功。所以我干脆就写了篇文章。把能搜集到的电子版也帮大家汇总了一下,取需!答读者问,能否推荐几本有价值的参考书 (含下载地址) (opens new window)**Github: https://github.com/yanfeizhang/ (opens new window)
飞哥写了一本电子书。这本电子书是对网络性能进行拆解,把性能拆分为三个角度:CPU 开销、内存开销等。具体到某个角度比如 CPU,那我需要给自己解释清楚网络包是怎么从网卡到内核中的,内核又是通过哪些方式通知进程的。只有理解清楚了这些才能真正把握网络对 CPU 的消耗。对于内存角度也是一样,只有理解了内核是如何使用内存,甚至需要哪些内核对象都搞清楚,也才能真正理解一条 TCP 连接的内存开销。除此之外我还增加了一些性能优化建议和前沿技术展望等,最终汇聚出了这本《理解了实现再谈网络性能》。在此无私分享给大家。下载链接传送门:**《理解了实现再谈网络性能》 (opens new window)另外飞哥经常会收到读者的私信,询问可否推荐一些书继续深入学习内功。所以我干脆就写了篇文章。把能搜集到的电子版也帮大家汇总了一下,取需!答读者问,能否推荐几本有价值的参考书 (含下载地址) (opens new window)**Github: https://github.com/yanfeizhang/ (opens new window)

文礼
这个问题其实还挺复杂的,严格来说不是一句 “会” 或者 “不会” 能说清楚的。在 linux 当中,socket 包括两类:使用网络的 socket,称为 Berkeley socket;不使用网络的 socket,称为 Unix domain socket。两者 API 结构很像,所以容易被混淆,但是其实不是一个东西。Unix domain socket 是为单机上跨进程通信,也就是 IPC 设计的。通信数据直接通过 kernel 在进程间交换,与网卡毫无关联。Berkeley socket 则使用网络协议栈,也就是遵从 OSI 那个七层模型。其中,网卡是处在最下面的物理层,在 linux 当中,这一层除了物理网卡,还包括 lo(loopback)设备,甚至还有一些软件虚拟 NIC,如 ipv4 到 ipv6 的网桥,虚拟机的虚拟网卡,或者当单个网卡要绑定多个 IP 地址时出现的虚拟网卡。在使用 Berkeley socket 的时候,和本机通信是否走网卡,取决于通信的两端,也就是两个 socket 的网络地址绑定情况。通常情况下,无论是绑定 127.0.0.1,还是绑定其它分配给本机的地址,都会对应路由表当中的 lo 设备,通信数据通过 kernel 直接传输,不会使用到物理网卡。但是如果我们修改路由表,让其不要使用 lo 设备而是使用物理网卡,则数据就会出现在网线上。

王小陆
先说结论:不走网卡,不走物理设备,但是走虚拟设备,loopback device 环回. 本机的报文的路径是这样的: 应用层 -> socket 接口 -> 传输层(tcp/udp 报文) -> 网络层 -> back to 传输层 -> backto socket 接口 -.> 传回应用程序 在网络层,会在路由表查询路由,路由表(软件路由,真正的转发需要依靠硬件路由,这里路由表包括快速转发表和 FIB 表)初始化时会保存主机路由 (host route,or 环回路由), 查询(先匹配 mask,再匹配 ip,localhost 路由在路由表最顶端,最优先查到)后发现不用转发就不用走中断,不用发送给链接层了,不用发送给网络设备(网卡)。像网卡发送接收报文一样,走相同的接收流程,只不过 net device 是 loopback device,最后发送回应用程序。这一套流程当然和转发和接收外网报文一样,都要经过内核协议栈的处理,不同的是本机地址不用挂 net device.
全文完
本文由 简悦 SimpRead (opens new window) 优化,用以提升阅读体验
使用了 全新的简悦词法分析引擎 beta,点击查看 (opens new window)详细说明